◆ ESSAY
2025년 7월, Firefox 141이 WebGPU를 정식 지원하면서 Chrome, Edge, Safari, Firefox 네 개 주요 브라우저 모두에서 WebGPU를 사용할 수 있게 됐다. WebGL이 2011년에 등장한 이후 14년 만의 브라우저 GPU API 세대교체다.
| 브라우저 | 지원 시작 | 비고 |
|---|---|---|
| Chrome | 2023년 4월 (v113) | Windows, macOS, ChromeOS |
| Edge | 2023년 4월 (v113) | Chrome과 동일 |
| Safari | 2025년 6월 (v26) | macOS, iOS, iPadOS, visionOS |
| Firefox | 2025년 7월 (v141) | Windows, macOS ARM64(v145) |
Chrome이 2년 먼저 지원했지만, Safari와 Firefox가 올해 연달아 합류하면서 이제 데스크톱 브라우저의 약 85%에서 WebGPU를 쓸 수 있다. 프로덕션에서 WebGPU를 고려해볼 만한 시점이 된 것이다.
WebGL은 2011년에 나온 API다. 14년 전이다. 그때는 iPhone 4S가 최신폰이었고, GPU는 지금과 비교하면 장난감 수준이었다. 문제는 그동안 GPU 하드웨어가 완전히 달라졌는데, WebGL은 그대로라는 것이다.
WebGL의 근본적인 문제는 두 가지다.
1. 상태 머신 방식
WebGL은 전역 상태를 계속 바꿔가면서 그린다. 뭔가를 그리려면 먼저 "현재 버퍼", "현재 텍스처", "현재 셰이더"를 설정하고, 그 다음에 draw 명령을 호출한다.
// WebGL: 전역 상태를 계속 변경
gl.bindBuffer(gl.ARRAY_BUFFER, buffer1)
gl.bindTexture(gl.TEXTURE_2D, texture1)
gl.useProgram(program1)
gl.drawArrays(gl.TRIANGLES, 0, 3) // 이 시점의 "현재 상태"로 그림
gl.bindBuffer(gl.ARRAY_BUFFER, buffer2) // 상태 변경
gl.bindTexture(gl.TEXTURE_2D, texture2) // 또 변경
gl.useProgram(program2) // 또 변경
gl.drawArrays(gl.TRIANGLES, 0, 3) // 바뀐 상태로 그림
매 draw 호출마다 드라이버가 "지금 뭐가 바인딩되어 있지? 셰이더 입력이랑 버퍼 레이아웃이 맞나?"를 검증한다. 이 오버헤드가 쌓이면 CPU 병목이 된다.
2. 즉시 실행 모델
WebGL은 API 호출이 즉시 드라이버로 전달된다. JavaScript에서 gl.bindBuffer()를 호출하면 그 즉시 드라이버가 상태를 변경한다. 명령 100개를 보내면 100번의 JS↔드라이버 왕복이 발생한다.
WebGPU는 이 문제를 두 가지 방식으로 해결한다.
1. 명시적 바인딩: 상태 머신 대신, 필요한 리소스를 미리 묶어서 파이프라인으로 만든다. 런타임에 상태 검증이 필요 없다.
2. 커맨드 버퍼: 명령을 즉시 실행하지 않고, 커맨드 버퍼에 기록해뒀다가 한 번에 GPU로 전송한다.
// WebGPU: 명령을 기록하고 한 번에 제출
const commandEncoder = device.createCommandEncoder()
const pass1 = commandEncoder.beginRenderPass(renderPassDescriptor1)
pass1.setPipeline(pipeline1) // 미리 컴파일된 파이프라인
pass1.setBindGroup(0, bindGroup1) // 리소스 묶음
pass1.draw(3)
pass1.end()
const pass2 = commandEncoder.beginRenderPass(renderPassDescriptor2)
pass2.setPipeline(pipeline2)
pass2.setBindGroup(0, bindGroup2)
pass2.draw(3)
pass2.end()
// 모든 명령을 한 번에 GPU로 전송
device.queue.submit([commandEncoder.finish()])
| 구분 | WebGL | WebGPU |
|---|---|---|
| 기반 기술 | OpenGL ES (2007년 설계) | Vulkan/Metal/D3D12 (2015년 이후) |
| 명령 처리 | 즉시 실행, 매번 검증 | 기록 후 일괄 제출 |
| 상태 관리 | 전역 상태 머신 | 명시적 바인딩 |
| 파이프라인 | 런타임 생성 | 미리 컴파일 |
| Compute Shader | 미지원 | 지원 |
| 멀티스레딩 | 불가능 | 가능 |
결과적으로 WebGPU는 JavaScript와 GPU 사이의 병목을 크게 줄인다. Babylon.js의 Snapshot Rendering 기능은 WebGPU에서 약 10배 빠른 렌더링을 달성했다. 물론 극단적인 최적화 케이스지만, 드로우 콜이 많은 복잡한 씬에서 WebGPU의 이점이 확실하다.
근데 사실 그래픽 성능은 부차적인 이야기다. WebGPU의 진짜 중요한 점은 Compute Shader를 지원한다는 것이다.
WebGL은 "그래픽"만 할 수 있다. 삼각형을 그리고, 텍스처를 입히고, 화면에 픽셀을 찍는 것. 그게 전부다. 범용 연산을 하려면 꼼수를 써야 했다. 데이터를 텍스처에 인코딩하고, 셰이더로 "그림을 그리는 척"하면서 연산을 수행하고, 결과를 다시 텍스처에서 읽어오는 식이다. 느리고 제약이 많다.
WebGPU는 처음부터 범용 GPU 연산(GPGPU)을 지원한다. Compute Shader를 쓰면 GPU를 "그래픽 카드"가 아니라 "병렬 연산 장치"로 쓸 수 있다. 수천 개의 코어가 동시에 행렬 곱셈을 수행하고, 텐서 연산을 처리한다.
이 셰이더 코드는 WGSL(WebGPU Shading Language)이라는 별도 언어로 작성한다. JavaScript가 아니라 GPU에서 실행되는 코드다. JS에서는 이 코드를 문자열로 전달해서 컴파일하고 실행한다.
// JavaScript에서 WGSL 셰이더를 문자열로 전달
const shaderCode = `
@group(0) @binding(0) var<storage, read> input_a: array<f32>;
@group(0) @binding(1) var<storage, read> input_b: array<f32>;
@group(0) @binding(2) var<storage, read_write> output: array<f32>;
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) id: vec3<u32>) {
let index = id.x;
output[index] = input_a[index] + input_b[index];
}
`
// GPU에서 셰이더 컴파일
const shaderModule = device.createShaderModule({code: shaderCode})
// 파이프라인 생성 및 실행
const pipeline = device.createComputePipeline({
layout: 'auto',
compute: {module: shaderModule, entryPoint: 'main'},
})
이게 브라우저에서 AI inference를 실용적으로 돌릴 수 있는 핵심이다. 머신러닝 모델은 결국 행렬 연산의 연속인데, 이걸 GPU에서 네이티브로 처리할 수 있게 된 것이다. 물론 TensorFlow.js나 Transformers.js 같은 라이브러리를 쓰면 이런 저수준 코드를 직접 작성할 필요는 없다.
그래서 실제로 얼마나 빨라질까?
TensorFlow.js는 WebGPU 백엔드에서 WebGL 대비 약 3배 빠른 inference 성능을 보여준다. 모델이 복잡할수록 격차가 더 벌어진다.
CPU에서 2-3초 걸리던 중간 크기 언어 모델 inference가 WebGPU로 200-400ms까지 줄어든다. 체감할 수 있는 수준이다.
| 백엔드 | Inference 시간 (상대값) | 비고 |
|---|---|---|
| CPU (WASM) | 10x | 기준 |
| WebGL | 3x | 텍스처 기반 연산 |
| WebGPU | 1x | Compute Shader |
브라우저에서 실용적으로 돌릴 수 있는 건 5-10B 파라미터 이하 모델이다. GPT-4급 모델은 당연히 안 된다. 하지만 다음과 같은 작업은 충분히 가능하다:
WebGPU를 직접 다루려면 셰이더 코드를 작성해야 하지만, 대부분의 경우 라이브러리를 쓰면 된다. WebGPU 백엔드를 지원하는 주요 라이브러리들을 소개한다.
Google에서 만든 브라우저/Node.js용 ML 라이브러리다. 가장 오래됐고 생태계가 넓다.
npm install @tensorflow/tfjs @tensorflow/tfjs-backend-webgpu
Hugging Face에서 만든 라이브러리다. Python의 transformers 라이브러리를 JavaScript로 포팅한 것으로, Hugging Face Hub의 모델들을 브라우저에서 바로 쓸 수 있다.
npm install @huggingface/transformers
pipeline() API, ONNX 기반Hugging Face Hub에서 ONNX 태그가 붙은 모델은 대부분 Transformers.js에서 사용 가능하다. Xenova 네임스페이스에 WebGPU 최적화된 모델들이 많다.
Microsoft에서 만든 ONNX 모델 실행 런타임이다. Transformers.js도 내부적으로 이걸 쓴다.
npm install onnxruntime-web
| 상황 | 추천 |
|---|---|
| NLP (임베딩, 분류, 요약) | Transformers.js |
| 이미지 분류/객체 감지 | Transformers.js 또는 TensorFlow.js |
| 커스텀 모델 학습 | TensorFlow.js |
| 기존 ONNX 모델 실행 | ONNX Runtime Web |
| 빠르게 프로토타입 | Transformers.js (pipeline() API) |
대부분의 경우 Transformers.js로 시작하는 걸 추천한다. pipeline() API가 직관적이고, WebGPU 설정도 {device: 'webgpu'} 한 줄이면 된다.
직접 해보자. TensorFlow.js의 WebGPU 백엔드로 간단한 inference를 돌려보는 예제다.
npm init -y
npm install @tensorflow/tfjs @tensorflow/tfjs-backend-webgpu
import * as tf from '@tensorflow/tfjs'
import '@tensorflow/tfjs-backend-webgpu'
async function initWebGPU() {
// WebGPU 지원 여부 확인
if (!navigator.gpu) {
console.error('WebGPU not supported')
return false
}
// WebGPU 백엔드 설정
await tf.setBackend('webgpu')
await tf.ready()
console.log('Backend:', tf.getBackend()) // 'webgpu'
return true
}
WebGPU의 성능 차이를 직접 확인해보자.
async function benchmark() {
const size = 1024
// 큰 행렬 생성
const a = tf.randomNormal([size, size])
const b = tf.randomNormal([size, size])
// 워밍업 (첫 실행은 컴파일 시간 포함)
const warmup = tf.matMul(a, b)
await warmup.data()
warmup.dispose()
// 실제 벤치마크
const iterations = 10
const start = performance.now()
for (let i = 0; i < iterations; i++) {
const result = tf.matMul(a, b)
await result.data() // GPU 연산 완료 대기
result.dispose()
}
const elapsed = performance.now() - start
console.log(`${size}x${size} matmul: ${(elapsed / iterations).toFixed(2)}ms`)
// 메모리 정리
a.dispose()
b.dispose()
}
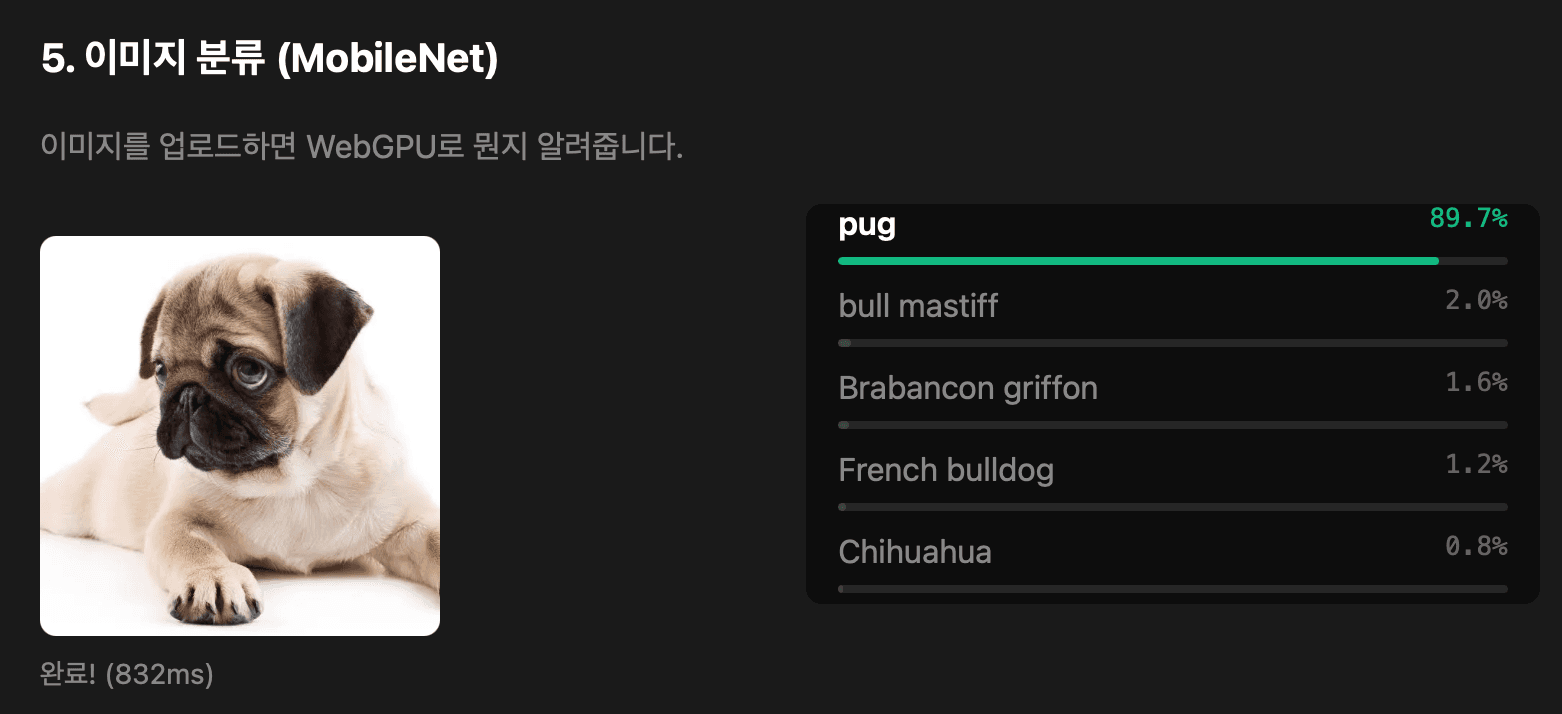
실제로 모델을 돌려보자. MobileNet으로 이미지 분류를 해본다.
import * as tf from '@tensorflow/tfjs'
import '@tensorflow/tfjs-backend-webgpu'
async function classifyImage(imageElement: HTMLImageElement) {
// WebGPU 초기화
await tf.setBackend('webgpu')
await tf.ready()
// MobileNet 모델 로드
const model = await tf.loadGraphModel(
'https://tfhub.dev/google/tfjs-model/imagenet/mobilenet_v3_small_100_224/classification/5/default/1',
{fromTFHub: true},
)
// 이미지 전처리
const tensor = tf.browser
.fromPixels(imageElement)
.resizeBilinear([224, 224])
.expandDims(0)
.div(255.0)
// Inference
const start = performance.now()
const predictions = model.predict(tensor) as tf.Tensor
const data = await predictions.data()
const elapsed = performance.now() - start
console.log(`Inference time: ${elapsed.toFixed(2)}ms`)
// Top 5 예측 결과
const top5 = Array.from(data)
.map((prob, i) => ({index: i, prob}))
.sort((a, b) => b.prob - a.prob)
.slice(0, 5)
// 메모리 정리
tensor.dispose()
predictions.dispose()
return {top5, inferenceTime: elapsed}
}
WebGL과 WebGPU 성능을 직접 비교해보고 싶다면:
async function compareBackends() {
const backends = ['webgl', 'webgpu']
const results: Record<string, number> = {}
for (const backend of backends) {
try {
await tf.setBackend(backend)
await tf.ready()
const size = 512
const a = tf.randomNormal([size, size])
const b = tf.randomNormal([size, size])
// 워밍업
const warmup = tf.matMul(a, b)
await warmup.data()
warmup.dispose()
// 벤치마크
const start = performance.now()
for (let i = 0; i < 20; i++) {
const r = tf.matMul(a, b)
await r.data()
r.dispose()
}
results[backend] = (performance.now() - start) / 20
a.dispose()
b.dispose()
} catch (e) {
console.log(`${backend} not available`)
}
}
console.table(results)
}
좀 더 실용적인 예제로, Transformers.js를 사용해서 텍스트 임베딩을 생성해보자. 검색, 유사도 비교, RAG 시스템에서 유용하게 쓸 수 있다.
import {pipeline} from '@huggingface/transformers'
async function generateEmbeddings(texts: string[]) {
// 임베딩 파이프라인 생성 (WebGPU 사용)
const extractor = await pipeline(
'feature-extraction',
'Xenova/all-MiniLM-L6-v2',
{device: 'webgpu'},
)
const start = performance.now()
// 임베딩 생성
const output = await extractor(texts, {
pooling: 'mean',
normalize: true,
})
const elapsed = performance.now() - start
console.log(`${texts.length} texts embedded in ${elapsed.toFixed(2)}ms`)
return output.tolist()
}
// 사용 예시
const texts = ['오늘 날씨가 좋다', '날씨가 화창하다', '주식 시장이 하락했다']
const embeddings = await generateEmbeddings(texts)
// 코사인 유사도 계산
function cosineSimilarity(a: number[], b: number[]) {
const dot = a.reduce((sum, val, i) => sum + val * b[i], 0)
const normA = Math.sqrt(a.reduce((sum, val) => sum + val * val, 0))
const normB = Math.sqrt(b.reduce((sum, val) => sum + val * val, 0))
return dot / (normA * normB)
}
console.log('날씨 문장 유사도:', cosineSimilarity(embeddings[0], embeddings[1]))
console.log('다른 주제 유사도:', cosineSimilarity(embeddings[0], embeddings[2]))
이미지 분류도 간단하다. ViT(Vision Transformer) 모델로 이미지가 뭔지 판별하는 예제다.
import {pipeline} from '@huggingface/transformers'
async function classifyImage(imageUrl: string) {
// 이미지 분류 파이프라인 생성 (WebGPU 사용)
const classifier = await pipeline(
'image-classification',
'Xenova/vit-base-patch16-224',
{device: 'webgpu'},
)
// 분류 실행
const results = await classifier(imageUrl, {topk: 5})
// 결과: [{label: 'golden retriever', score: 0.95}, ...]
return results
}
// 사용 예시
const results = await classifyImage('/path/to/image.jpg')
console.log(results[0].label) // 가장 높은 확률의 라벨
console.log(results[0].score) // 확률 (0~1)
파일 업로드, URL, 또는 canvas 요소를 넘기면 된다. 모델은 첫 로드 시 다운로드되고 (ViT-base 기준 약 350MB), 이후엔 브라우저에 캐시된다.
WebGPU로 브라우저에서 AI를 돌릴 수 있게 되면 뭐가 좋을까?
핵심은 민감한 데이터를 서버로 보내지 않아도 된다는 것이다.
회사에서 기밀 문서를 요약하거나 번역하고 싶다고 하자. ChatGPT나 Claude API를 쓰면 문서 내용이 외부 서버로 나간다. 보안 정책상 이게 안 되는 회사가 많다. WebGPU를 쓰면 모델을 브라우저로 가져와서, 문서는 로컬에서 처리할 수 있다. 데이터가 디바이스를 떠나지 않는다.
이런 시나리오에서 유용하다:
모델을 한 번 다운로드하면 네트워크 없이도 inference를 돌릴 수 있다. Service Worker와 조합하면 완전한 오프라인 AI 앱을 만들 수 있다.
생각해보면 유용한 시나리오가 많다:
"특정 유스케이스에서는 이미 실용적이다"라고 했는데, 구체적으로 뭘까?
1. 텍스트 임베딩 & 시맨틱 검색
앞서 예제로 보여준 것처럼, 텍스트를 벡터로 변환하는 건 이미 실용적이다. all-MiniLM-L6-v2 같은 모델은 22MB 정도로 작고, 브라우저에서 충분히 빠르게 돌아간다. 블로그 검색, 문서 유사도 비교, 간단한 RAG 시스템에 쓸 수 있다.
2. 이미지 분류 & 객체 감지
MobileNet, EfficientNet 같은 경량 모델로 이미지 분류가 가능하다. "이 사진에 고양이가 있나?" 정도는 브라우저에서 실시간으로 판단할 수 있다. 웹캠으로 실시간 객체 감지도 된다.
3. 음성 인식
Whisper tiny/base 모델로 음성을 텍스트로 변환할 수 있다. 정확도는 서버 모델보다 떨어지지만, 간단한 음성 메모나 명령어 인식에는 충분하다.
4. 소형 LLM 채팅
Phi-3, Gemma 2B 같은 소형 언어 모델을 브라우저에서 돌릴 수 있다. 응답 속도는 느리지만 (토큰당 수십~수백 ms), 간단한 질의응답이나 텍스트 생성에 쓸 수 있다. WebLLM 프로젝트가 이걸 잘 보여준다.
물론 한계도 명확하다:
| 한계 | 설명 |
|---|---|
| 모델 크기 | 브라우저 메모리 제한, 큰 모델은 다운로드 시간도 문제 |
| 디바이스 편차 | 저사양 기기에서는 느리거나 안 돌아감 |
| 배터리 | 모바일에서 GPU 사용은 배터리 소모가 큼 |
| 모델 보안 | 모델이 클라이언트에 노출됨 (모델 탈취 가능) |
| 정확도 | 서버의 대형 모델보다 정확도가 낮음 |
결국 "모든 AI를 브라우저에서"가 아니라, "적합한 유스케이스를 선별해서"가 맞는 접근이다.
WebGPU가 모든 주요 브라우저에서 지원되면서, 브라우저에서 실용적인 수준의 AI를 돌릴 수 있게 됐다. 텍스트 임베딩, 이미지 분류, 간단한 음성 인식 정도는 이미 프로덕션에서 고려해볼 만하다.
핵심은 두 가지다:
1. 개인정보 보호가 중요한 경우
2. 오프라인 동작이 필요한 경우
관심 있다면 TensorFlow.js나 Transformers.js의 WebGPU 백엔드로 직접 실험해보면 된다. 생각보다 설정이 간단하고, 성능 차이를 체감할 수 있다.
# TensorFlow.js
npm install @tensorflow/tfjs @tensorflow/tfjs-backend-webgpu
# Transformers.js
npm install @huggingface/transformers

판단을 비싸게 만든 마찰이, 동시에 판단을 못 배우게 만든다. AI 시대에 가장 비싸지는 능력이 가장 덜 길러지는 이유

직군의 경계가 무너진다는 말은 절반만 맞다. 무너지는 건 생산이고, 판단과 책임은 오히려 남는다.

스펙을 만족하고 버그를 고칠 수 있다면 코드를 읽을 줄 몰라도 될까. 이해는 사라지는 게 아니라 어디로 이동하는지를 따진다.

Bun이 Claude Code로 6일 만에 Zig에서 Rust로 옮긴 사건. 코드 품질보다 OSS 거버넌스와 자원 비대칭의 의미가 더 크다.