◆ ESSAY
다음은 실제 개발자분이 보내주신 피드백입니다.
완전 강력하게 추천하고 싶어요 !!
4-1-1 내용 중, 서버(HydrationBoundary)에서 데이터를 패칭하지 않고 CSR로 전환하면 체감 속도 개선 효과를 기대할 수 있을 것이라는 내용이 있었습니다. 실제로 두 상황을 비교해보았어요.
측정 방법은 로컬 서버 환경에서 layout.tsx에서 window.performance.mark("page-start")를 실행하고, 렌더링된 후 측정하고 싶은 컴포넌트인 MemoView의 useEffect내 에서 performance.measure("MemoView mount", "page-start")를 실행해 두 값을 비교했습니다.
https://guesung.notion.site/HydrationBoundary-22289de02fde80ba80e0d289de1569cf?pvs=74
위 링크의 내용과 같이 HydrationBoundary를 제거하기 전과 후의 시간 차이는 미비했으며, 네트워크 속도가 느린 환경에서는 서버에서 데이터 패칭을 할 때 훨씬 빠른 속도를 보여주었습니다. 그래서 성능 최적화를 위해서 CSR로 이관하는 내용에 대해서 공감이 안되어서 질문을 드립니다.
혹시 제가 잘못 알고 있거나, 측정 방법이 잘못되었으면 알려주시면 감사하겠습니다.
현재 구조처럼 SSR에서 데이터를 미리 fetch하고, 렌더링은 클라이언트에서 수행하는 방식은 명확한 장단이 있습니다. 데이터 패칭 속도는 서버 환경에 따라 일정하게 유지되지만, 실제 렌더링 시점은 hydration 이후로 밀리기 때문에 체감 속도에서는 불리할 수 있습니다.
이때 고려할 수 있는 선택지는 아래와 같습니다:
CSR에서 Skeleton UI와 함께 fetch/render를 병행하는 구조: 이 경우 사용자의 기기 성능이나 네트워크 환경이 느리다면 로딩 지연이 더 크게 체감될 수 있지만, LCP 측면에서는 Skeleton이 빠르게 표시되어 긍정적인 지표를 만들 수 있습니다. 다만 제가 클라이언트에서 패칭하는 경우 속도가 이렇게 까지 느려질줄은 미처 몰랐는데요 (ㅠㅠ) 이러한 상황이라면 1번의 방식이 크게 도움이 안될 수도 있습니다만, 한번 꼼꼼하게 살펴보시고 판단하시면 좋을 것 같습니다/
SSR 시점에서 fetch + render까지 모두 수행하는 구조: 이 전략은 메모 데이터를 일정 길이까지만 잘라서 SSR HTML에 포함시키고, 추가 내용은 CSR에서 로드하는 방식으로 절충할 수 있습니다. 현재는 메모 길이 상관없이 모두 불러와서 아마도 성능에 문제가 있었을 것으로 보입니다. 실제로 메모 UI가 달력 대비 복잡하지 않은 구조 이면서 별로 무겁지 않다면, SSR에 포함시켜도 렌더링 비용은 크지 않을 것으로 판단됩니다.
현재 구조 유지 (SSR fetch, CSR render): 지금 구조는 fetch 는 서버에서, 렌더링은 완전히 클라이언트에서 하는 구조입니다만, SSR을 했음에도 LCP에는 기여 못하고 있어서 조금 애매하다고도 생각합니다. 물론 구조상 React Query prefetch나 안정적인 데이터 응답 면에서는 장점도 있긴 한데, 서버에서 최소한 스켈레톤이라도 렌더링해주는 방법도 고려해볼 수 있을 것 같아요.
결국 중요한 것은 메모를 SELECT해오고 제공하는데 병목이 있다고 생각이 들었습니다.
이 문제가 아마도 가장 큰 문제일 것 같고, 위 세가지는 이 문제를 해결하기 위한 임시방편이 아닐까 싶습니다.
그래서 구조가 어떻게 되었든 간에, SELECT쿼리를 튜닝하거나, 혹은 메모를 더 빠르게 가져올 수 있는 최적화 방안을 고민해보시는게 좋을 것 같습니다. (limit, 텍스트 자르기, 보다 가까운 리전에 DB 구축 등..)
정확한 해답보다는, 지금 상황에서 어느 선택지가 trade-off가 맞는지 보는 게 중요한 것 같아요. (원하시는 명확한 해답은 아닐 것 같아 미리 죄송하다는 말씀 드립니다.)
다음은 실제 개발자 분에게 전달 드린 글 입니다. 모두 공개 가능하다고 하셔서 별도 처리 없이 다 공개했습니다.
Disclaimer
본 요약 내용은 제공된 www.web-memo.site 웹사이트 성능 분석 보고서(2025년 6월 28일 12시 기준)를 바탕으로 주요 사항을 간추린 것입니다. 분석 시점 이후 웹사이트의 업데이트나 환경 변화에 따라 실제 상태와는 차이가 있을 수 있습니다. 이번 분석은 브라우저에 배포되고 번들된 결과물과 더불어 실제 소스 코드 까지 참고해서 분석하였기 때문에 이전 분석 대비 더 정확하게 분석할 수 있었습니다.
제시된 성능 병목 지점 및 개선 방안은 일반적인 권장 사항이며, 실제 적용 시 효과는 웹사이트의 구체적인 구현 방식, 서버 환경, 트래픽 패턴 등 다양한 요인에 따라 달라질 수 있습니다. 본 요약은 정보 제공을 목적으로 하며, 제안된 내용을 적용함에 따른 최종적인 결정과 그 결과에 대한 책임은 웹사이트 관리 주체에게 있습니다.
보다 상세한 분석 내용, 방법론, 그리고 전체 컨텍스트는 원본 분석 보고서를 참고해주시기 바랍니다.
안녕하세요! https://www.web-memo.site/ 웹사이트가 더욱 빠르고 안정적인 사용자 경험을 제공할 수 있도록, 현재 배포 중인 서비스에 대한 성능 분석 결과를 핵심 위주로 요약해드렸습니다.
web-memo 웹사이트는 현대적인 SSR 기반 아키텍처와 최신 프론트엔드 기술 스택을 잘 활용하고 있으며, 그 기술 수준 역시 현직자로 보아도 손색이 없을 정도로 매우 뛰어납니다. 다만 일부 구조적 한계와 서버리스 환경의 제약으로 인해 초기 로딩 지연 및 불필요한 리소스 비용이 발생하고 있는 상태입니다.
주요 성능 병목 지점은 다음과 같습니다.
getMemos()에서 limit 없이 전체 데이터를 SSR 시점에 fetch → 초기 렌더링 지연 및 hydration payload 증가react-big-calendar의 리렌더링 병목 및 next/dynamic 컴포넌트의 지연 로딩이에 따라 다음과 같은 개선 방안을 우선적으로 제안드립니다.
getMemos()에 limit을 적용하고 infinite scroll 도입을 권장합니다.MemoCalendar 커스텀 렌더러 최적화 및 불필요한 리렌더 방지dynamic 컴포넌트는 미리 import하여 사용자 인터랙션 지연 최소화이러한 개선 사항들을 적용하시면 SSR 및 초기 렌더링 성능, 네트워크 응답 속도, 렌더링 안정성 측면에서 실질적인 체감 개선 효과를 기대할 수 있습니다. 자세한 기술적 맥락과 근거는 본문 보고서를 참고해주시기 바랍니다.
2025년 6월 28일 기준 배포된 웹사이트를 분석해보았습니다. 웹 사이트의 특성상, 다른 서비스 분석과는 다르게 Desktop 모드로 분석을 수행하였습니다.
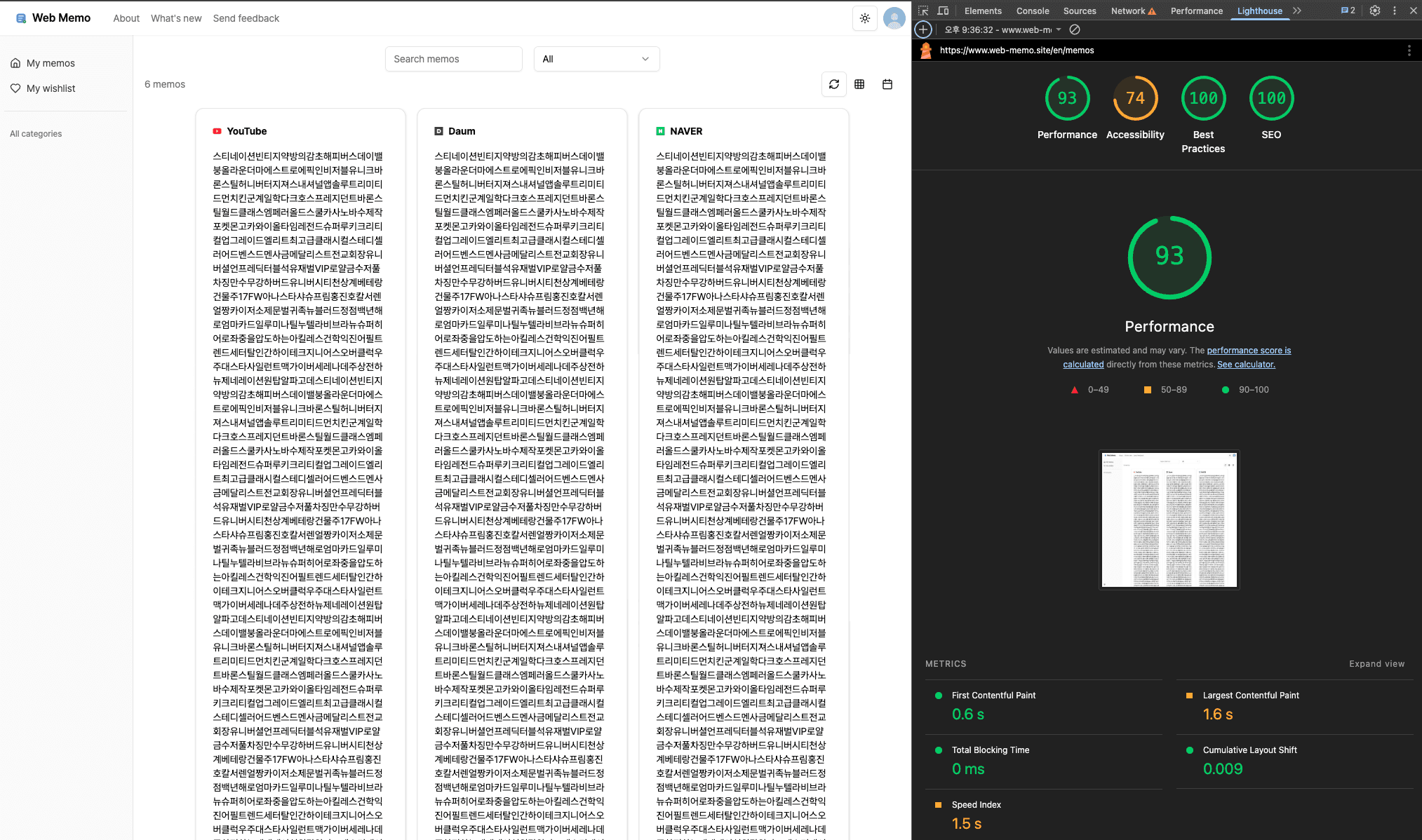
분석에 사용한 도구는 다음과 같습니다.
다른 분석과는 다르게, 로그인이 필요한 서비스였기 때문에 webpageTest 분석은 수행하지 못했습니다.
원래 보고서 작성 시에는 빌드된 결과물만 보고 기술 스택을 유추해야 하지만, 본 분석에서는 저장소 주소를 제공받아 소스코드를 직접 확인할 수 있었기 때문에 별도의 추론 과정 없이 정확한 기술 스택을 파악할 수 있었습니다.
https://github.com/guesung/Web-Memo
저장소 내용을 바탕으로 간단하게 요약하자면 다음과 같습니다.
이 프로젝트는 Next.js 14.2.10, React 18.3.1을 기반으로 구성되어 있으며, App Router 구조를 적극 활용하고 있습니다. 상태 및 데이터 관리를 위해 React Query(5.59.0), React Hook Form(7.53.2), Supabase 클라이언트가 사용되며, 다국어 지원은 i18next와 next-i18next 조합으로 처리되고 있습니다.
UI는 TailwindCSS를 중심으로 구성되어 있으며, 사용자 경험 강화를 위해 Framer Motion, Lucide React, Driver.js 등이 함께 사용됩니다. 또한 Sentry를 통한 오류 추적이 통합되어 있고, 관련 설정은 .cursor/rules/tech-stack.mdc 파일에 명시되어 있습니다.
전체 저장소는 Turborepo 기반의 모노레포로 구성되어 있으며, 패키지 매니저로는 pnpm(9.5.0)을 사용합니다. 웹앱은 Next.js 기반으로 빌드되고, 크롬 확장 프로그램은 Vite(5.3.3)를 통해 번들링됩니다. 테스트는 Vitest와 Playwright를 함께 사용하고 있으며, 실행 환경은 Node.js 18.12.0 이상을 요구합니다.
이 저장소는 Next.js 기반의 웹 애플리케이션과 Vite 기반의 크롬 확장 기능을 하나의 모노레포에서 통합 관리하며, 프론트엔드 최신 기술 스택과 품질 관리 체계를 균형 있게 갖춘 구조로 볼 수 있습니다.
https://www.web-memo.site/ 는 현재 Vercel 플랫폼을 통해 배포 및 서비스되고 있는 웹사이트입니다. 도메인 등록 기관은 Gabia이며, 도메인은 ns1.vercel-dns.com, ns2.vercel-dns.com을 사용하는 Vercel DNS 네임서버에 위임되어 있습니다.
HTTP 응답 헤더(curl -I https://www.web-memo.site)를 통해 server: Vercel, x-vercel-id 등의 정보를 확인할 수 있으며, 이는 Vercel에서 해당 요청을 직접 처리하고 있다는 명확한 증거입니다. 도메인 루트 접근 시에는 HTTP/1.0 308 Permanent Redirect를 통해 HTTPS로 리디렉션되고 있으며, HTTPS 환경에서 Vercel이 직접 응답하고 있습니다.
.vercel.app 서브도메인으로는 접근이 불가능하며, 해당 프로젝트는 custom domain을 통해서만 접근 가능하도록 구성된 것으로 보입니다. 실제 서비스는 Vercel의 App Router 기반 SSR 아키텍처로 구성되어 있으며, 정적 자산과 dynamic chunk는 모두 Vercel CDN을 통해 전달되고 있습니다.
따라서 이 웹사이트는 도메인 관리, DNS 설정, 배포 및 CDN까지 모두 Vercel 인프라 위에서 구성된 현대적인 Jamstack 아키텍처 기반 서비스로 판단됩니다.
개발자님께서 말씀해주신 첫 페이지 로딩 지연 문제의 근본 원인을 파악하고, 우선적으로 개선해야 할 지점들을 구체적으로 분석해보았습니다.
서버사이드 렌더링 기반 웹사이트에서 첫 페이지 로딩이 느려지는 주된 원인은 서버 응답 지연과 초기 렌더링 병목입니다. 백엔드 API 호출 지연, 복잡한 서버 렌더링 로직, 캐시 전략 부재 등이 대표적인 요인들입니다. 다만 이런 성능 문제는 서버 내부에서 발생하기 때문에 브라우저 도구만으로는 정확한 원인 파악에 한계가 있습니다. Lighthouse나 Chrome DevTools는 클라이언트에서 관측되는 결과만 보여줄 뿐, 서버에서 실제로 무엇이 병목인지는 알려주지 않습니다. 이상적으로는 서버 로그, APM 데이터, 백엔드 레이턴시 분석 등 서버 내부 지표가 함께 있어야 정확한 진단이 가능합니다. 하지만 외부에서 접근할 수 있는 정보로는 이런 데이터를 얻기 어렵습니다. 그래도 다행히 소스 코드를 확인할 수 있어서, 코드 구조상 성능 병목이 될 가능성이 높은 지점들을 찾아볼 수 있었습니다. 실제 서버 상황을 완전히 파악할 수는 없지만, 구조적으로 개선 가능한 부분들을 중심으로 분석해드리겠습니다.
/memos 렌더링을 과정의 await 병목현재 /memos 페이지는 SSR을 기반으로 구성되어 있으며, layout.tsx와 page.tsx에서 다음과 같은 서버사이드 요청이 순차적으로 발생합니다:
// layout.tsx
const isUserLogin = await new AuthService(supabaseClient).checkUserLogin();
if (!isUserLogin) redirect(PATHS.login);
await initSentryUserInfo({ lng });
<HydrationBoundaryWrapper
queryKey={QUERY_KEY.category()}
queryFn={() => new CategoryService(supabaseClient).getCategories()}
>
<MemoSidebar />
</HydrationBoundaryWrapper>
// page.tsx
<HydrationBoundaryWrapper
queryKey={QUERY_KEY.memos()}
queryFn={() => new MemoService(supabaseClient).getMemos()}
>
<MemoView />
</HydrationBoundaryWrapper>
각 await 호출은 Supabase를 통한 네트워크 요청으로 구성되어 있으며, React Query 기반의 prefetch 구조로 인해 모든 쿼리가 완료되기 전까지 SSR HTML 생성이 지연됩니다. 이로 인해 Time to First Byte(TTFB) 및 Largest Contentful Paint(LCP) 지표에 영향을 줄 수 있습니다.
다만 현재 코드에 대해 쉽게 개선 제안을 드리기 어려웠던 이유는, Next.js App Router, React Server Components(RSC), React Query prefetch 구조 등 현대적인 SSR 아키텍처의 권장 방식을 충실히 따르고 있었기 때문입니다. 인증 확인, 사용자 설정, 사이드바 렌더링 등의 역할이 명확히 분리되어 있으며, 유지보수성과 확장성을 고려한 구조로 판단되는, 현직자로 보아도 손색이 없는 훌륭한 코드였습니다.
그러나 성능 최적화를 중심으로 살펴볼 경우, 다음과 같은 구조적 한계가 존재합니다:
메모 UI는 <Suspense>로 감싸진 클라이언트 컴포넌트(MemoView) 내부에서 렌더링되므로, SSR HTML에는 실제 메모 콘텐츠가 포함되지 않습니다.
반면, getMemos()는 SSR 시점에서 실행되어 전체 메모 데이터를 React Query의 hydration을 위해 미리 fetch합니다.
아래는 테스트용으로 삽입한 대용량 메모 데이터가 실제 HTML에 포함되지는 않지만, 직렬화된 상태로 클라이언트로 전달되는 예시입니다. 이는 서버에서 데이터 fetch가 완료되었음을 의미합니다.
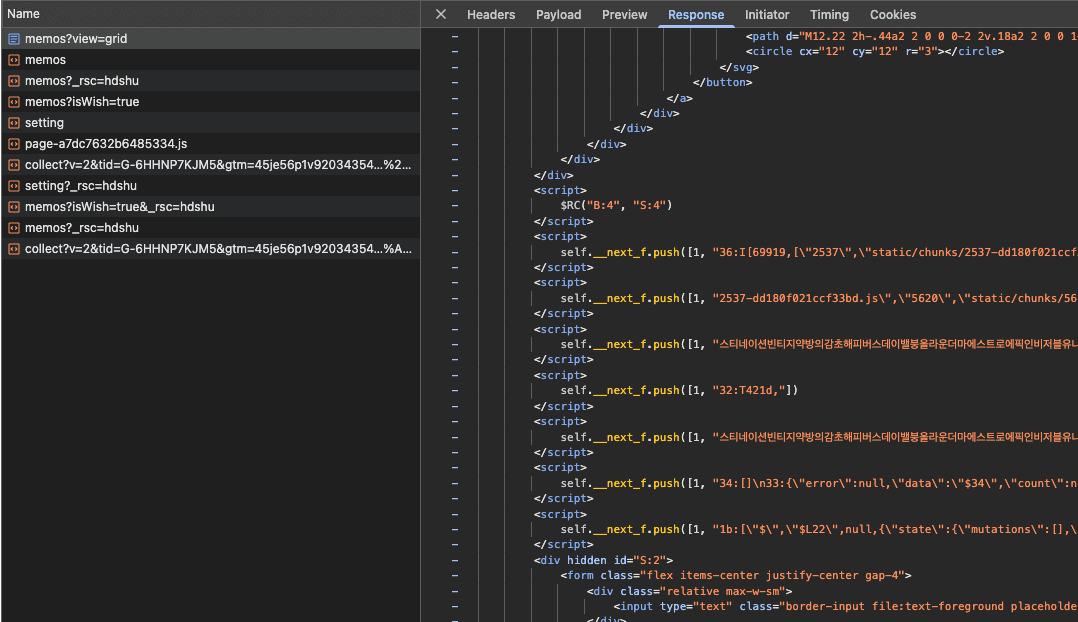
또한 HTML 캡처에 따르면, 실제 메모 리스트 영역은 SSR HTML에 존재하지 않고, 다음과 같이 Suspense fallback과 함께 클라이언트 렌더링을 기다리는 구조입니다:
<div hidden id="S:5">
<div class="flex w-full flex-col gap-4">
<div class="flex items-center">
<div class="flex w-full items-center justify-between">
<p class="text-muted-foreground select-none text-sm">메모 5개</p>
<div class="flex">
<!--$!-->
<template data-dgst="BAILOUT_TO_CLIENT_SIDE_RENDERING"></template>
<!--/$-->
<!--$!-->
<template data-dgst="BAILOUT_TO_CLIENT_SIDE_RENDERING"></template>
<!--/$-->
</div>
</div>
</div>
<div class="relative h-full w-full">
<div
class="bg-primary/20 pointer-events-none fixed left-0 top-0 z-[40] h-[1px] w-[1px] origin-top-left"
></div>
<div
class="container h-screen max-w-full pb-48 will-change-transform"
id="memo-grid"
>
<div></div>
</div>
</div>
</div>
</div>
즉, 렌더링은 클라이언트에서 수행되고 있음에도 불구하고, 데이터 fetch는 SSR에서 선행되고 있는 구조이며, 이는 실제 시각적 콘텐츠가 생성되지 않는 상태에서 SSR 대기 비용만 발생하고 있다는 점에서 비효율적일 수 있습니다.
따라서 성능 최적화를 우선순위로 둘 경우, /memos 페이지의 메모 데이터를 완전히 클라이언트에서 fetch 및 렌더링하는 구조로 전환하는 것이 유리합니다. 그 이유는 다음과 같습니다.
다만 현재 구조를 CSR 구조로 전환하면 초기 로딩 시 콘텐츠 공백이 발생할 수 있으므로, 아래와 같은 UI 전략을 병행해 적용하는 것이 효과적이라고 생각합니다.
앞서 말씀드린 것 처럼 현재 /memos 페이지의 SSR 구조는 기능적, 구조적으로 충분히 잘 설계되어 있으며, 현대적인 NextJS App Router 아키텍처의 기준을 잘 따르고 있습니다.
그러나 성능 최적화를 중점적으로 고려할 경우, 메모 데이터를 CSR로 이관하고 Skeleton UI 및 콘텐츠 제한 전략을 함께 적용하는 것이 TTFB, LCP, CLS 등 핵심 Web Vitals 지표를 실질적으로 개선하는 데 도움이 됩니다. 이러한 구조 전환은 단순한 SSR 포기가 아니라, SSR의 장점을 유지하면서 병목 지점을 해소하는 방향의 전략적 리팩토링 이 될 수 있다고 생각합니다.
현재 /memos 페이지의 SSR 렌더링 과정에서는 useTranslation() 훅을 통해 i18next 인스턴스를 매 요청마다 새로 생성하고, 언어별 번역 리소스를 동적으로 import하여 초기화하고 있습니다. 해당 구조는 다음과 같이 구성되어 있습니다:
const initI18next = async (language: Language, namespace?: Namespace) => {
const i18nInstance = createInstance(); // 인스턴스 매번 새로 생성
await i18nInstance
.use(initReactI18next)
.use(
resourcesToBackend((language: Language) =>
import(`./locales/${language}/translation.json`)
)
)
.init(getOptions(language, namespace));
return i18nInstance;
};
export default async function useTranslation(...) {
const i18nInstance = await initI18next(language, namespace);
return {
t: i18nextInstance.getFixedT(
language,
Array.isArray(namespace) ? namespace[0] : namespace,
options?.keyPrefix,
),
i18n: i18nextInstance,
};
}
이 코드는 요청이 들어올 때마다 새로운 i18n 인스턴스를 생성하고, 번역 JSON을 import()로 로딩합니다.
Node.js는 일반적으로 동일 프로세스 내에서 import()된 모듈을 캐싱하지만, 해당 서비스는 다음과 같은 제약 환경에 놓여 있습니다:
curl -I https://www.web-memo.site
HTTP/2 307
cache-control: public, max-age=0, must-revalidate
content-type: text/plain
date: Sat, 28 Jun 2025 04:57:34 GMT
location: /memos
server: Vercel
strict-transport-security: max-age=63072000
x-vercel-id: icn1::2w69g-1751086654787-0015380b2120
curl -I https://www.web-memo.site 요청 결과에 따르면, 이 서비스는 Vercel 서버리스 플랫폼에서 동작 중입니다:
서버리스 환경에서는 다음과 같은 특성이 있습니다:
import('./locales/ko/translation.json')과 같은 번역 리소스 로딩은 매 요청마다 I/O 및 초기화 비용이 반복적으로 발생하게 됩니다.이 구조는 SSR 초기화 과정에서 TTFB(Time to First Byte) 지연으로 이어질 수 있습니다. 실제 측정 결과, 영문 기준 번역 리소스 크기는 약 8.4KB, 한글 기준은 약 10.5KB이며, JSON 크기는 작지만 i18n 초기화 비용과 동적 import의 누적 I/O 비용이 성능 병목의 주된 원인이 될 수 있습니다.
추가로, 번역 리소스가 /locales/{lang}/translation.json 형태로 소스코드 내부에 포함되어 있어:
이는 다국어 지원 확장, 외부 번역 시스템 연동, 실시간 AB 테스트 등에서 제약이 될 수 있습니다.
따라서 번역 리소스에 대해서는 다음과 같은 내용을 제안해드립니다.
i18n 인스턴스를 요청 간 재사용할 수 있도록 캐싱 구조로 전환합니다. 글로벌 scope에 언어별로 초기화된 i18n 인스턴스를 저장해두고, 이후 동일 언어 요청에서는 기존 인스턴스를 재사용함으로써 .createInstance()와 .init()의 반복 호출을 방지할 수 있습니다.
번역 리소스를 메모리에서 재사용할 수 있도록 명시적으로 캐싱합니다. 현재는 import()로 매번 JSON을 동적으로 로딩하고 있으나, 이를 require()와 함께 Map, lru-cache 등의 구조로 캐싱하면 cold start가 아닌 경우에는 불필요한 I/O를 피할 수 있습니다. (지금 구조면 map 정도로도 충분할 것 같네요.)
// `import()` + `Map`을 이용한 비동기 캐싱
const translationCache = new Map<string, any>()
export const loadTranslation = async (lang: string) => {
if (translationCache.has(lang)) return translationCache.get(lang)
const resource = await import(`./locales/${lang}/translation.json`)
translationCache.set(lang, resource.default ?? resource)
return resource.default ?? resource
}
번역 리소스를 CDN 또는 외부 저장소에 분리 배포하고, fetch 기반으로 로딩합니다. S3, Vercel Blob, Edge Functions 등을 활용하면 번역 리소스를 애플리케이션 코드와 분리해 독립적으로 관리할 수 있으며, CDN 캐싱을 통해 전세계 사용자에게 빠르게 전달할 수 있습니다.
페이지별로 필요한 namespace만 선택적으로 로딩하도록 구조를 개선합니다. 모든 페이지에서 동일한 번역 데이터를 로딩하기보다는, 실제 사용하는 범위에 한정된 namespace만 초기화하여 불필요한 초기화 시간과 JSON 용량을 줄일 수 있습니다. 지금 구조에서는 언어의 양 자체가 크지 않아 크게 도움이 되지 않을 수도 있습니다.
결론적으로 현재의 i18n 구조는 기능적으로는 문제 없지만, 매 요청마다 i18n 인스턴스를 새로 생성하고 번역 리소스를 동적 import하는 구조는 특히 서버리스 환경에서 SSR TTFB 지연의 주요 원인이 될 수 있습니다. 또한 번역 리소스를 소스 코드에 포함한 채 import하는 방식은 배포 유연성, CDN 활용, 외부 번역 시스템 연동 등 운영 측면에서의 제약이 존재합니다.
이에 따라, i18next 인스턴스 및 번역 리소스를 명시적으로 캐싱하거나, CDN 기반 리소스 로딩 구조로 전환하는 전략을 적용함으로써 SSR 성능도 챙기고 서비스의 영문/한글 지원을 원활하게 할 수 있습니다.
getMemos의 갯수 제한 및 infinite scroll 도입현재 /memos 페이지의 SSR 렌더링 과정에서는 getMemos() 메서드를 통해 Supabase에서 모든 메모를 한 번에 가져오고 있습니다:
getMemos = async () =>
this.supabaseClient
.schema(SUPABASE.table.memo)
.from(SUPABASE.table.memo)
.select('*, category(id, name, color)')
.order('created_at', {ascending: false})
이 쿼리는 limit() 없이 전체 메모를 불러오며, 해당 호출은 HydrationBoundaryWrapper 내부에서 SSR prefetch로 수행되기 때문에, 이 구조는 앞서 설명한 SSR 구조와 마찬가지로, HTML이 생성되기 전까지 이 데이터 전체를 기다리는 구조입니다.
문제는 MemoView 컴포넌트는 실제로 클라이언트에서 Suspense를 통해 렌더링되기 때문에, 서버에서 데이터를 모두 미리 가져오는 이 구조는 SSR 응답 지연 및 hydration payload 증가로 이어질 수 있습니다.
특히 메모 수가 수백 개 이상으로 증가할 경우,
등의 성능 저하가 발생할 수 있습니다. 따라서 다음과 같은 개선을 제안드립니다:
limit)하고, 이후는 무한스크롤이나 "더보기" 버튼을 통해 점진적으로 로딩
getMemos = async () =>
this.supabaseClient
.schema(SUPABASE.table.memo)
.from(SUPABASE.table.memo)
.select('*, category(id, name, color)')
.order('created_at', {ascending: false})
.limit(20)
useInfiniteQuery 또는 cursor 기반 로딩 구조로 연동이러한 구조로 전환하면 SSR 시점의 네트워크 병목을 줄이고, 유저가 실제로 보는 화면에 필요한 데이터만 우선 제공함으로써 체감 성능(LCP, TTFB) 개선 효과를 기대할 수 있습니다.
현재 /memos 페이지에서는 사용자 인증 상태를 middleware와 layout.tsx 두 곳에서 각각 확인하고 있습니다.
middleware.ts에서 updateAuthorization()을 통해 checkUserLogin() 호출layout.tsx 진입 시 다시 한 번 checkUserLogin()을 호출하여 인증 상태를 확인이러한 구조는 기능적으로는 문제가 없지만, SSR 성능과 유지보수 관점에서는 명백한 비효율이 발생합니다.
그렇다면 어디서 확인하는 것이 좋을까요? 이 방식에는 정답이 없다고 생각합니다. 제가 생각하는 두 구조의 장단점은 다음과 같습니다.
| 처리 위치 | 장점 | 단점 |
|---|---|---|
| middleware | - SSR 이전 빠른 리다이렉트 가능 - 경로 보호 확실 | - Supabase 호출이 HTML 응답을 지연 - React 컴포넌트에서 상태 공유 불가능 |
| layout.tsx | - 인증 정보 Context로 공유 가능 - React 기반 사이드이펙트(Sentry 등) 연계 용이 | - 인증 실패 시 리다이렉트까지 일부 HTML 렌더링이 진행될 수 있음 |
만약에 제가 개발자라면, 그리고 현재처럼 Sentry 초기화, Sidebar 렌더링 등에서 인증된 사용자 정보를 계속 활용하는 구조라면, layout.tsx에서 인증을 수행하고, middleware에서는 locale/경로 리디렉션만 담당하는 것이 더 적합합니다. middleware는 경량한 경로 처리용, layout은 React context 및 인증 기반 UI 분기 처리용으로 역할을 분리하는 것이 가장 유연하고 확장 가능한 구조라고 판단됩니다.
다만 이는 개인의 선택에 따라 달려 있을 뿐, 어디에 두는 것이 적절할지는 정답은 없다고 생각합니다. 다만 명백하게 중복 호출되고 있는 구조임으로, 로그인 체크를 한 단계에서 수행하는 것이 적절해보입니다.
앞선 4-1-4 항목에서는 로그인 인증을 middleware와 layout.tsx에서 중복 확인하고 있다는 점을 짚었는데,
이 구조는 사용자 정보를 가져오는 Supabase 호출이 총 세 번 발생한다는 점에서도 비효율적입니다.
layout.tsx에서 checkUserLogin() 호출 → 내부적으로 getUser() 사용initSentryUserInfo()에서 다시 getUser() 호출<InitSentryUserInfo /> 컴포넌트가 동일한 요청을 한 번 더 수행하나의 요청 처리 과정에서 Supabase API가 세 번 호출되고 있으며, 이 중 두 번은 완전히 동일한 사용자 정보를 얻기 위한 중복 호출입니다. Supabase는 외부 네트워크 요청이기 때문에 서버리스 환경에서는 cold start 지연과 함께 전체 SSR 성능에 부정적인 영향을 줄 수 있습니다.
이 문제는 구조적으로 정리할 수 있습니다. checkUserLogin() 대신 처음부터 getUser()를 호출해 사용자 정보를 받아오고, 그 결과를 필요한 모든 흐름에서 재사용하면 됩니다. 예를 들어 아래와 같이 구조를 변경할 수 있습니다:
const supabaseClient = getSupabaseClient()
const {data: user} = await new AuthService(supabaseClient).getUser()
if (!user) redirect(PATHS.login)
// 사용자 정보가 있으므로 서버에서 Sentry 설정 가능
setUser({
id: user.id,
email: user.email,
username: user.identities?.[0]?.identity_data?.name,
ip_address: '{{auto}}',
})
setTag('lng', lng)
이렇게 하면 Supabase 호출은 한 번만 발생하고, 그 결과를 Sentry 초기화뿐 아니라 Sidebar, 사용자 context 등에서 공유할 수 있습니다.
한편, Supabase 클라이언트 자체도 현재는 supabaseClient라는 캐시 변수만 선언되어 있지만 실제 할당이 없어 매번 새 인스턴스를 생성하고 있습니다:
let supabaseClient: MemoSupabaseClient;
export const getSupabaseClient = () => {
if (supabaseClient) return supabaseClient;
const cookieStore = cookies();
return createServerClient<Database, "memo", Database["memo"]>(
CONFIG.supabaseUrl,
CONFIG.supabaseAnonKey,
{ cookies: { ... } },
);
};
위 코드는 의도상으로는 클라이언트를 한 번만 생성해 재사용하려는 구조처럼 보이지만, supabaseClient = ... 할당이 빠져 있기 때문에 캐싱이 되지 않습니다. 이를 다음과 같이 수정하면 클라이언트 객체 생성 비용도 줄일 수 있습니다:
let supabaseClient: MemoSupabaseClient
export const getSupabaseClient = () => {
if (supabaseClient) return supabaseClient
const cookieStore = cookies()
supabaseClient = createServerClient<Database, 'memo', Database['memo']>(
CONFIG.supabaseUrl,
CONFIG.supabaseAnonKey,
{
cookies: {
getAll() {
return cookieStore.getAll()
},
setAll(cookiesToSet) {
cookiesToSet.forEach(({name, value, options}) =>
cookieStore.set(name, value, options),
)
},
},
db: {schema: SUPABASE.table.memo},
},
)
return supabaseClient
}
이런 식으로 사용자 정보(getUser() 결과)와 Supabase 클라이언트 모두를 한 번만 생성해 재사용하면, SSR 시점의 네트워크 요청과 리소스 생성이 줄어들고, 구조도 훨씬 단순해질 수 있습니다. 다만 Vercel처럼 요청 단위로 컨텍스트가 초기화되는 환경에서는, 이러한 캐싱이 구조적인 이점은 있어도, 실질적인 성능 이득은 크지 않을 수 있습니다.
여기서 한 가지 더 고려할 점은 await initSentryUserInfo()의 위치입니다. 이 함수는 Supabase에서 사용자 정보를 가져와 Sentry에 설정하는데, 현재는 이 작업이 끝날 때까지 SSR이 대기하게 됩니다. 로그 정확성이라는 장점은 있지만, 초기 렌더링 성능에는 병목이 됩니다. 만약 서버에서 Sentry에 사용자 컨텍스트를 꼭 남겨야 할 필요가 없다면, 이 작업을 클라이언트에서 처리하거나 병렬 처리로 전환하는 것도 고려할 수 있습니다. 다만 이 경우 서버 측 에러 로그에 사용자 정보가 누락될 수 있으므로 서비스 특성에 따라 trade-off를 판단해야 합니다.
결론적으로 이 구조는 인증 여부를 어디서 확인할지(4-1-4)를 넘어서, 사용자 정보를 어떻게 한 번만 가져오고 전역적으로 재사용할 것인가에 대한 설계 문제입니다. 같은 데이터를 여러 번 요청하는 현재 구조는 SSR 성능에 직접적인 영향을 주기 때문에, 사용자 정보는 한 번만 fetch해서 필요한 곳에 명확히 전달하는 방식으로 구조를 단순화하는 것이 바람직합니다.
앞서 언급한 핵심 병목 요소들 외에도, 전반적인 성능 향상에 기여할 수 있는 세부 최적화 지점들을 추가로 분석해보았습니다.
현재 MemoCalendar 컴포넌트에서는 Day.js의 로케일(locale) 데이터를 다음과 같이 동적으로 import하고 있습니다:
dayjs.extend(timezone)
const localizer = dayjsLocalizer(dayjs)
// 동적 로딩
import('dayjs/locale/en')
import('dayjs/locale/ko')
이 방식은 실행 시점에 로케일 모듈을 비동기로 로드하게 되며, hydration 이후까지 로케일 적용이 보장되지 않습니다. 브라우저 네트워크가 느릴 경우 깜빡이거나 locale이 적용되기 전 캘린더가 먼저 렌더링되는 현상이 발생할 수 있고, 페이지 전환 시 추가 fetch가 일어나 초기 실행 비용도 늘어납니다.
또한 Next.js나 Vite 빌드 환경에서는 정적 import 만이 번들 최적화 대상이 되므로, 위 구조는 별도의 chunk 분리가 되지 않아 런타임 비용이 고정적으로 발생하게 됩니다.
따라서 아래와 같이 정적 import로 변경하는 것이 더 바람직합니다:
import 'dayjs/locale/en'
import 'dayjs/locale/ko'
dayjs.extend(timezone)
const localizer = dayjsLocalizer(dayjs)
이렇게 하면 로케일 모듈이 빌드 시점에 번들에 포함되며, 런타임에 추가 네트워크 요청 없이 바로 사용할 수 있습니다. 특히 캘린더 초기 렌더링 시점을 제어하기 어려운 상황에서는 로케일이 미리 포함되어 있는 것이 안정성과 일관성 면에서 유리합니다.
로케일 수가 많지 않고, 변경 가능성도 크지 않다면 정적 import 방식이 가장 단순하면서도 안정적인 구조입니다. 향후 언어 수가 많아질 경우에는 tree-shaking 가능한 구조로 리팩터링하거나, 빌드 시점에 사용하는 언어만 추출하는 스크립트를 함께 고려할 수 있습니다.
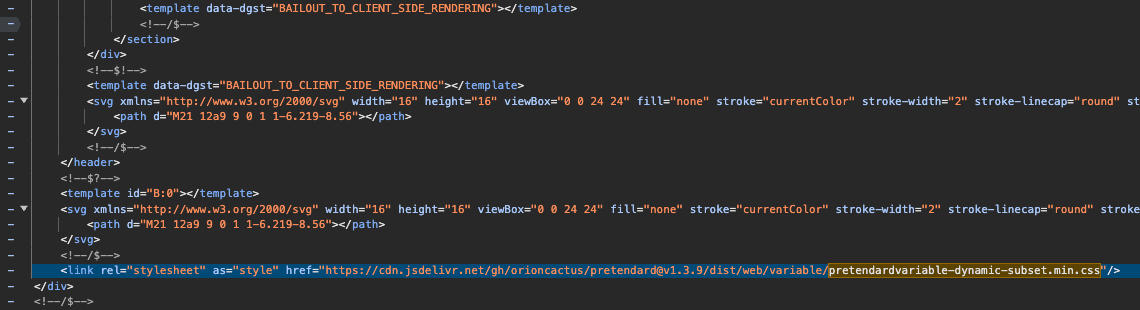
현재 pretendard 웹폰트를 아래와 같이 불러오고 있다는 것을 확인하였습니다.
<link
rel="stylesheet"
as="style"
href="https://cdn.jsdelivr.net/gh/orioncactus/pretendard@v1.3.9/dist/web/variable/pretendardvariable-dynamic-subset.min.css"
/>
as="style" 속성이 붙어 있긴 하지만, rel="stylesheet"는 기본적으로 렌더링을 차단하는 방식이기 때문에 실제로는 HTML 파싱이 멈추고 이 CSS를 기다리게 됩니다. Lighthouse에서도 렌더링 차단 리소스로 지적되고 있습니다.
더 큰 문제는 해당 <link> 태그가 app/[lng]/layout.tsx의 컴포넌트 내부에 <div>와 함께 들어가 있다는 점입니다. 이는 HTML 문법상 올바르지 않은 위치이며, 브라우저에 따라 무시되거나 예외적으로 처리될 수 있습니다. 결과적으로 폰트가 의도한 시점에 적용되지 않거나, 성능 최적화가 무력화될 수 있습니다.
이 문제를 해결하려면 웹폰트를 비동기로 불러오도록 하고, 위치도 HTML <head> 안으로 옮겨야 합니다. 일반적으로는 preload와 onload 속성을 활용해 아래와 같이 처리합니다:
<link
rel="preload"
as="style"
href="https://cdn.jsdelivr.net/gh/orioncactus/pretendard@v1.3.9/dist/web/variable/pretendardvariable-dynamic-subset.min.css"
onload="this.onload=null;this.rel='stylesheet'"
/>
<noscript>
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/gh/orioncactus/pretendard@v1.3.9/dist/web/variable/pretendardvariable-dynamic-subset.min.css"
/>
</noscript>
이 방식은 초기 렌더링을 차단하지 않으면서도 폰트를 적용할 수 있도록 도와줍니다. 자바스크립트가 꺼져 있는 환경에서도 <noscript>를 통해 fallback이 동작하기 때문에 비교적 안전합니다. 다행히 Pretendard CSS에는 font-display: swap 설정이 포함되어 있어 FOIT 문제는 발생하지 않습니다.
다만 이 방식도 몇 가지 단점이 있습니다.
onload 이벤트가 발생해야 스타일이 적용되기 때문에, 네트워크 상태에 따라 폰트 적용이 늦어질 수 있으며 FOUT이 더 눈에 띌 수 있습니다.<link>의 onload를 지원하지 않아 폰트가 적용되지 않을 수 있습니다. 다만 이정도로 오래된 브라우저는 사용자도 거의 사용하지 않으므로 크게 신경쓰지 않으셔도 될 것 같습니다.결론적으로, 현재 layout.tsx 컴포넌트 내부 <div> 안에 <link> 태그를 삽입한 구조는 HTML 문법상 올바르지 않으며, 브라우저에 따라 무시되거나 의도치 않은 방식으로 처리될 수 있습니다. 이는 실제 렌더링 시점에서 폰트 적용이 지연되거나 누락되는 원인이 될 수 있으며, 렌더링 차단 해소를 위한 최적화도 무력화될 가능성이 있습니다.
특히 Next.js App Router 구조에서는 <head>를 설정할 수 있는 유일한 위치가 app/layout.tsx이므로, app/[lng]/layout.tsx 내부에서 <link>를 삽입하는 현재 방식은 구조적으로도 적절하지 않습니다.
따라서 웹폰트 로딩은 반드시 app/layout.tsx의 <head> 영역에서 수행되어야 하며, 가능하면 preload + onload 패턴을 통해 렌더링 차단 없이 비동기 로딩되도록 구성하는 것을 권장드립니다.
소스 코드를 분석하던 중, 차트 관련 기능을 사용하지 않고 있음에도 불구하고 recharts 관련 리소스가 클라이언트로 전송되고 있다는 점이 의아했습니다.
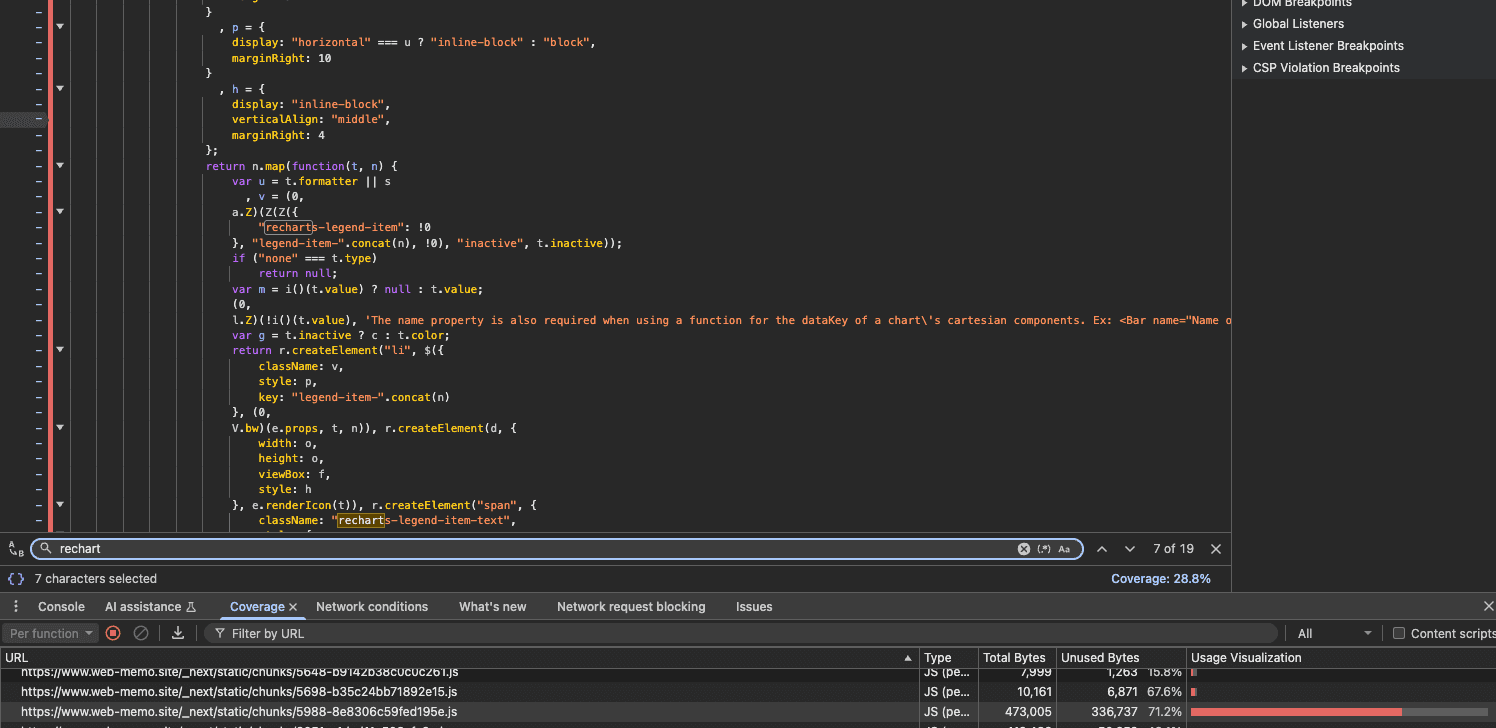
문제를 파악하기 위해 내부 코드를 살펴본 결과, 해당 프로젝트는 @web-memo/ui라는 내부 UI 패키지를 통해 재사용 가능한 컴포넌트를 제공하고 있었고, 이 패키지에서 recharts를 의존성으로 포함한 뒤 아래와 같이 export 하고 있었습니다.
'use client'
import * as React from 'react'
import * as RechartsPrimitive from 'recharts'
// 중략
export {
ChartContainer,
ChartLegend,
ChartLegendContent,
ChartStyle,
ChartTooltip,
ChartTooltipContent,
}
하지만 실제로는 이 컴포넌트를 사용하는 곳이 전혀 없었고, package.json에도 sideEffects: false가 설정되어 있었습니다. 그럼에도 recharts 관련 코드가 번들에 포함된 이유는 단순히 ESModule 여부 때문이 아니었습니다. (참고로 type: "module"을 추가해도 문제는 해결되지 않습니다.)
해당 UI 패키지는 여러 단계를 거친 barrel export 구조를 사용하고 있었고, 이로 인해 Webpack이 모듈 사용 여부를 정적으로 분석하지 못하고 전체 recharts 모듈을 포함한 것으로 보입니다.
Next.js는 ESM 환경에서 export * from 구문이 과도하게 중첩될 경우, 사용 여부를 정적으로 분석하지 못해 트리쉐이킹이 정상적으로 동작하지 않을 수 있습니다. 이는 Webpack이 import 경로를 따라 정확한 dependency graph를 구성하지 못하고, 중간에 위치한 barrel 파일을 전체 블록으로 간주해 해당 모듈의 모든 내용을 포함시켜버리는 방식 때문입니다.
Webpack 에서는 sideEffects: false와 같은 옵션을 통해 안전한 트리쉐이킹을 도울 수 있지만, 복잡하게 중첩된 barrel export 구조에서는 이러한 최적화가 제한적이거나 위 사례처럼 제대로 동작하지 않을 수 있습니다.
다행히도 이 문제는 Next.js의 experimental.optimizePackageImports 기능을 사용하여 해결할 수 있었습니다.
// next.config.js
experimental: {
optimizePackageImports: ['@web-memo/ui'],
}
이 설정은 지정된 패키지의 import 경로를 flatten된 형태로 재작성하여, Webpack이 정적으로 사용 여부를 판단할 수 있도록 만들어 줍니다. 그 결과 실제로 사용되지 않는 recharts export가 제거되었고, 다음과 같이 번들 사이즈가 크게 감소했습니다:
| 경로 | 변경 전 First Load JS | 변경 후 First Load JS | 감소량 |
|---|---|---|---|
/[lng]/login | 334 kB | 103 kB | -231 kB |
/[lng]/memos | 470 kB | 339 kB | -131 kB |
/[lng]/setting | 422 kB | 266 kB | -156 kB |
이처럼 사용하지 않는 컴포넌트의 의존성이 의도치 않게 번들에 포함되는 현상은, 실제 서비스 성능에 영향을 줄 수 있음에도 쉽게 드러나지 않기 때문에 특히 주의가 필요합니다.
그리고 현재 프로젝트는 모든 내부 패키지가 ESModule로 작성되어 있으므로, 불필요한 barrel 파일보다는 exports 필드를 사용해 각 컴포넌트를 명시적으로 내보내는 방식이 더 적합합니다. Next.js 가 제공하는 옵션인 optimizePackageImports는 매우 유용하지만, 빌드 시간에 부담을 줄 수 있고, 누락 시 실수로 이어질 가능성도 있으므로 처음부터 ESModule 기반으로 패키지를 설계하는 것이 근본적인 해결책입니다. 배럴파일 보다는 package.json의 exports 필드를 사용하여 배럴 파일 없이 내보내주세요.
여기에 더해 개인적으로는, 내부 UI 패키지를 소스 코드 형태로 직접 참조하기보다는 사전에 빌드된 결과물을 참조하는 구조가 더 적합하다고 생각합니다. 빌드 결과를 눈으로 확인할 수 있어 문제를 빠르게 파악할 수 있고, 각 패키지 단위로 캐싱이나 변경 추적, 테스트 격리 등의 관리 측면에서도 더 유리하기 때문입니다. 다만 이렇게 구성하면 확인해야 할 지점이 명확히 나뉘게 되므로, 개발자가 빌드 구조와 의존성 흐름을 충분히 이해하고 있어야 디버깅이 수월합니다.
MemoCalendar의 최적화현재 MemoCalendar는 리렌더링에 매우 취약한 구조를 가지고 있으며, 실제로 사용자 인터랙션과 무관한 전체 리렌더링이 빈번하게 발생하고 있는 것으로 확인됩니다. 아래는 React DevTools의 리렌더 시각화 기능을 통해 캘린더 아이템 클릭 시 불필요한 렌더링이 발생하는 장면을 캡처한 예시입니다.

아이템을 클릭했을 때 화면상 변화는 전혀 없지만, react-big-calendar 전체가 다시 렌더링되고 있으며, 이는 다음과 같은 원인들에 기인합니다:
handleItemClick)가 searchParams를 참조하고 있음 → 핸들러가 매 렌더마다 재생성되며 onSelectEvent 변경으로 Calendar 전체 리렌더링 유발Calendar의 커스텀 렌더러(event, dateHeader, agenda.date, toolbar)가 모두 inline 함수로 전달되고 있음 → 내부 diff 최적화 무력화이러한 구조적 문제를 해소하고 성능을 개선하기 위해 다음과 같은 리팩터링을 제안합니다.
searchParams를 제거하고 URLSearchParams(window.location.search)를 직접 사용const handleItemClick = useCallback(
(event: ExtendedEvent) => {
const params = new URLSearchParams(window.location.search)
params.set('id', event.id)
router.push(`?${params.toString()}`, {scroll: false})
},
[router],
)
이렇게 하면 handleItemClick은 더 이상 매 렌더마다 새로 만들어지지 않고, onSelectEvent로 전달해도 Calendar는 불필요하게 리렌더링되지 않습니다. useSearchParams를 사용한 이유는 충분히 이해되지만, query paramter 가 렌더링에 영향을 미치지 않으며, 현재와 같이 단순히 주소를 읽고 푸시하는 목적이라면 이 방식이 더 안정적이며, 성능에도 유리합니다.
React.memo()로 분리const MemoEvent = memo(({event}: {event: ExtendedEvent}) => (
<div className="text-center">{event.title}</div>
))
이렇게 하면 렌더러 함수가 고정된 참조를 유지하게 되어, react-big-calendar 내부의 불필요한 셀/이벤트 재렌더링을 줄일 수 있습니다.
react-big-calendar는 기능이 풍부한 만큼 렌더 비용이 큰 컴포넌트입니다. 따라서 props 참조 최적화, 불필요한 상태 분리, 렌더링 경량화가 병행되지 않으면 체감 성능 저하로 이어질 수 있습니다. 위와 같은 구조로 리팩터링을 적용하면, 클릭이나 뷰 전환 등 잦은 사용자 인터랙션에서도 불필요한 렌더링 없이 부드럽고 안정적인 사용자 경험을 제공할 수 있습니다.
next/dynamic으로 로딩되는 캘린더를 prefetch흔히 Next.js에서 prefetch는 next/link를 통해 페이지 단위에서만 가능한 것으로 알고 있지만, 그렇지 않습니다. next/dynamic을 통해 lazy-load되는 컴포넌트도 명시적으로 import()를 호출해주면, 해당 컴포넌트의 chunk를 미리 로드(prefetch)할 수 있습니다.
아래 스크린샷은 dynamic으로 불러온 컴포넌트의 JS chunk가 언제 네트워크 요청되는지를 보여줍니다.
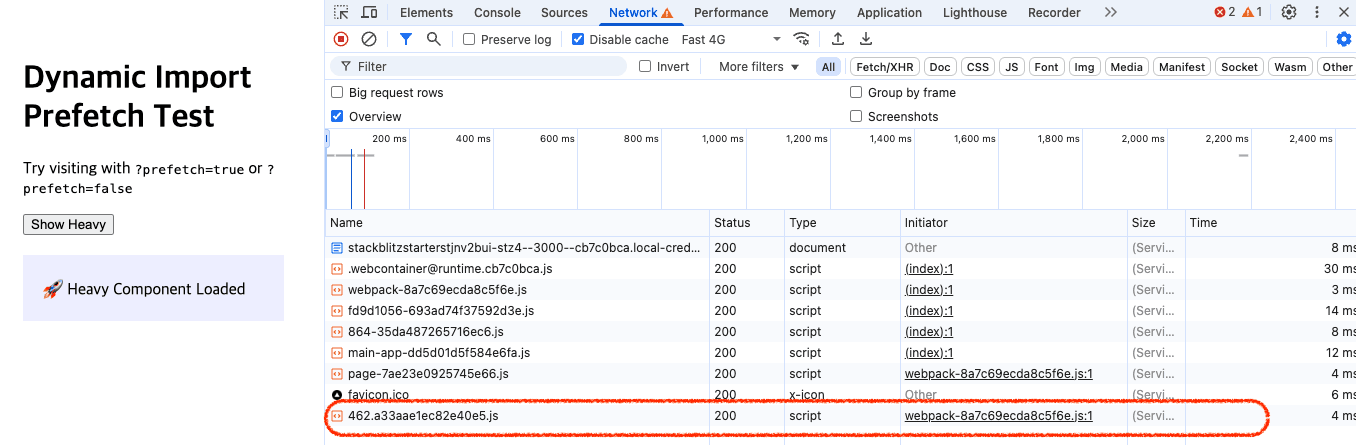
이 예시는 일반적인 동작 방식입니다. 캘린더 컴포넌트를 dynamic으로 불러오고, 버튼 클릭 시 렌더링하도록 구성했을 경우, 사용자가 클릭하는 순간 chunk가 네트워크를 통해 로드됩니다. 이때 chunk 파일의 크기가 크면 클수록 클릭 이후 렌더링까지의 지연이 발생하게 됩니다.
아래는 같은 컴포넌트를 사용하지만, useEffect를 통해 미리 import()를 호출하여 chunk를 사전 로드한 예시입니다.
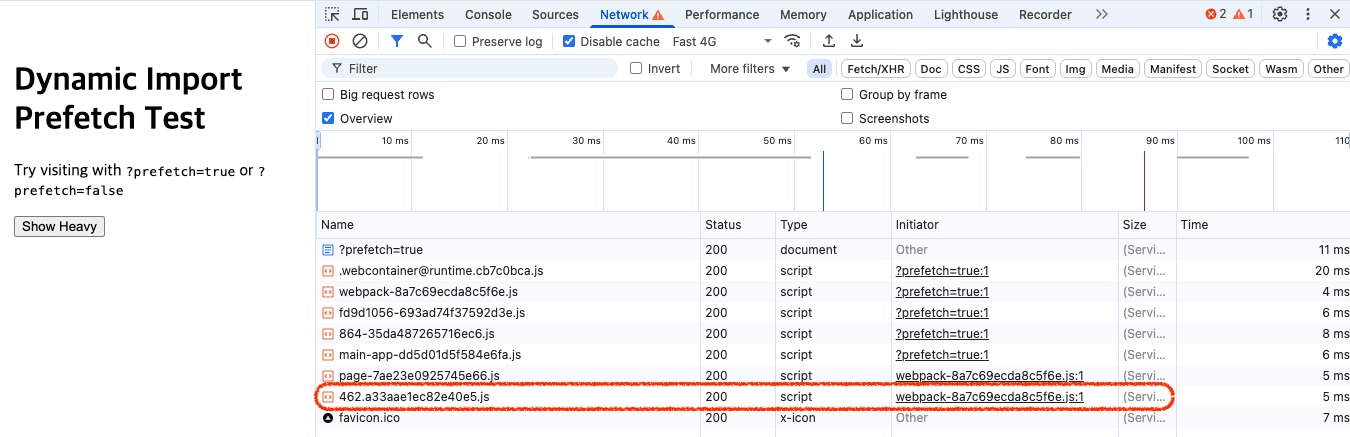
컴포넌트가 실제로 렌더링되기 전이지만, 리소스는 이미 브라우저에 로드된 상태입니다. chunk가 미리 로드되었기 때문에, 사용자가 클릭하여 캘린더 뷰를 활성화하는 순간 곧바로 렌더링이 시작됩니다. 아래 스크린샷은 이러한 상황을 보여줍니다.
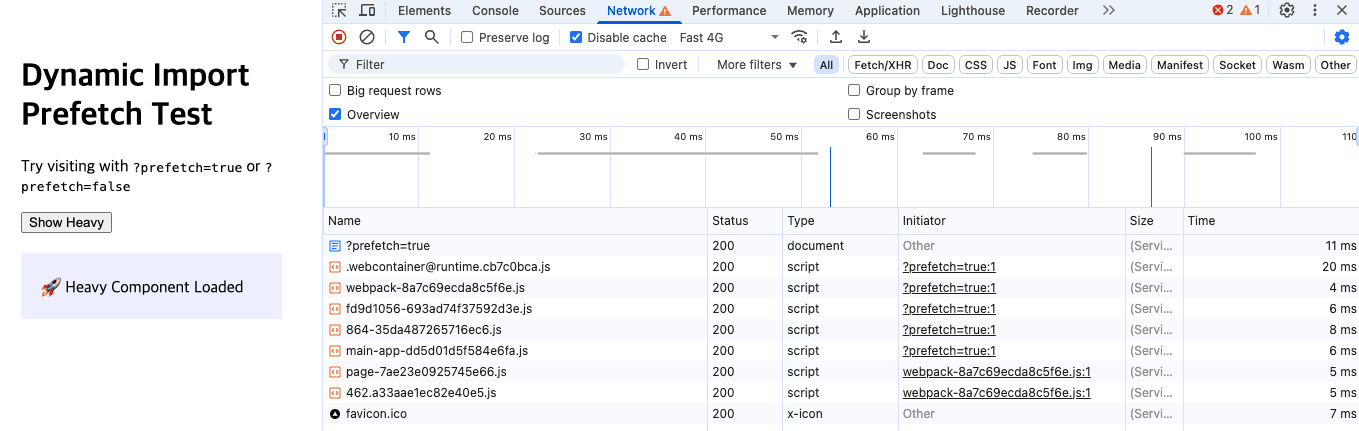
결과적으로 컴포넌트의 초기 렌더링 시점을 늦추지 않으면서도, 리소스는 미리 로드해둘 수 있기 때문에 체감 반응성을 향상시킬 수 있습니다.
dynamic으로 불러오는 컴포넌트라고 하더라도, 필요한 시점보다 조금 일찍 import()를 호출해주는 것만으로도 충분히 성능 개선 효과를 얻을 수 있습니다.
이는 페이지 전환이 아닌, 동일한 뷰 안에서 뷰 전환("grid" → "calendar")을 구현할 때 특히 효과적입니다. chunk 크기가 크거나 초기 렌더링에 많은 시간이 걸리는 컴포넌트일수록, prefetch 전략의 효과는 더욱 뚜렷하게 나타납니다. 실제로는 MemoView 컴포넌트 내부에서 아래와 같이 useEffect를 활용하면 됩니다:
useEffect(() => {
if (view === 'grid') {
import('./MemoCalendar')
}
}, [view])
이처럼 dynamic으로 불러오는 컴포넌트라고 하더라도, 필요한 시점보다 조금 앞서 import()를 호출해주는 것만으로도 충분한 성능 개선 효과를 얻을 수 있습니다. chunk 크기가 크거나 초기 렌더링에 시간이 걸리는 컴포넌트일수록 prefetch 전략의 효과는 더욱 분명하게 나타납니다.
https://docs.sentry.io/product/sentry-basics/performance-monitoring/
현재 프로젝트에는 Sentry가 이미 도입되어 있습니다. 그러나 현재 구조는 에러 추적 위주로 구성되어 있어, SSR 성능 병목을 정량적으로 분석하기에는 다소 한계가 있습니다. SSR 초기 로딩 지연의 원인을 보다 정확히 파악하려면, Sentry의 Performance 기능을 함께 활용하는 것을 추천드립니다.
Sentry Performance는 다음과 같은 방식으로 SSR 병목을 계측할 수 있습니다:
layout.tsx, page.tsx 내부의 주요 구간별 startTransaction 및 span을 설정하여 SSR 처리의 단계별 실행 시간을 기록다음과 같이 계측할 수 있습니다.
// 현재 구조와 동떨어진 예시 코드입니다.
import * as Sentry from '@sentry/nextjs'
const transaction = Sentry.startTransaction({name: 'SSR /memos'})
Sentry.getCurrentHub().configureScope((scope) => scope.setSpan(transaction))
const getUserSpan = transaction.startChild({op: 'auth', description: 'getUser'})
await getUser()
getUserSpan.finish()
const getMemosSpan = transaction.startChild({
op: 'query',
description: 'getMemos',
})
await getMemos()
getMemosSpan.finish()
transaction.finish()
이런 방식으로 Sentry에서 각 SSR 요청의 전체 처리 시간, 병목 단계, cold start 여부 등을 시각화할 수 있으며, Vercel 서버리스 환경에서는 요청별 실행 컨텍스트가 분리되므로, 각 요청의 병목 구간을 시각화하는 데 특히 효과적입니다.
이미 에러 추적 목적으로 Sentry가 통합되어 있으므로, Performance 트랜잭션 기능을 함께 도입하시면 추가적인 비용 없이 다음과 같은 이점을 기대할 수 있습니다:
TTFB, getMemos(), i18n, Sentry 설정 등 각 처리 단계별 속도 비교현재 프로젝트처럼 SSR 구조가 정돈되어 있는 경우, 간단한 트랜잭션 계측만으로도 충분히 많은 인사이트를 얻을 수 있으므로, 실제 원인 파악 및 성능 개선 우선순위 선정에 실질적인 도움이 될 것입니다.
이번 분석은 http://www.web-memo.site/ 프로젝트의 구조를 바탕으로, 성능 최적화 관점에서 개선 가능한 지점들을 구체적으로 정리해본 시도였습니다. 토이 프로젝트라고 보기 어려울 정도로, 이 웹사이트는 최신 프론트엔드 기술 스택과 구조적인 설계가 인상적이었으며, 코드 한 줄 한 줄에서 개발자의 고민과 높은 완성도를 느낄 수 있었습니다.
Next.js App Router, React Query, Supabase, i18n, 모노레포 구성 등 현대적인 기술이 잘 어우러져 있었고, 역할 분리 또한 명확하게 이루어져 있었습니다. 이 프로젝트는 단순한 실험을 넘어, 모던 프론트엔드 개발의 좋은 사례로 손색이 없습니다.
물론 현실적인 제약으로 인해 모든 영역을 완벽하게 최적화하긴 어렵지만, 작은 구조 개선이나 리소스 처리 방식의 변화만으로도 사용자 경험을 체감할 수 있을 정도로 개선할 수 있습니다. 특히 Sentry의 Performance 기능을 함께 활용하면, 어떤 부분이 실제 병목인지 실측 기반으로 확인하고, 향후 개선 우선순위를 정하는 데 큰 도움이 될 것입니다.
앞으로 이 프로젝트가 더 성장하거나 새로운 방향으로 확장될 때, 이번 분석이 참고가 되기를 바랍니다.
궁금한 점이나 함께 이야기 나누고 싶은 주제가 있다면 언제든 편하게 말씀해주세요.
읽어주셔서 감사합니다!


