◆ ESSAY
브라우저에서 웹사이트를 보여주기 위해 무언가를 하기전에, 먼저 브라우저가 어디로 가는지 알아야 한다. 주소 표시줄에 URL을 입력하거나, 페이지 또는 다른 앱의 링크를 클릭하거나, 즐겨찾기를 클릭하는 등 다양한 방법으로 웹사이트에 접근할 수 있다. 어떤 경우든, 결국 navigation이라는 과정이 일어나게 된다. 소위 이 탐색이라는 과정은, 웹 사이트를 상호작용하는 과정의 첫 번째 단계이며, 이 후에 웹 페이지 로드에 필요한 이벤트가 연쇄적으로 일어난다.
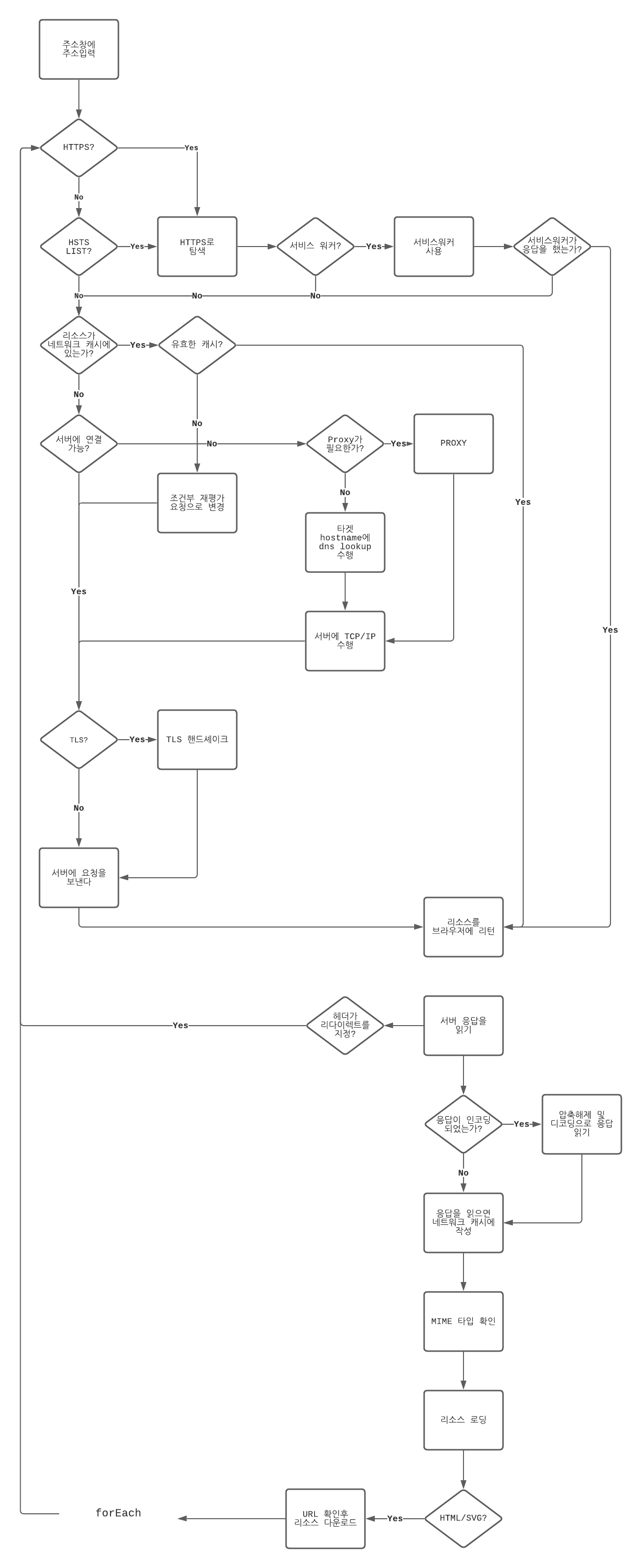
브라우저에 로딩해야할 URL이 주어지면, 아래 몇가지 일이 일어난다.
https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
먼저 쁘라우저는 URL이 HTTP 방식을 지정하는지를 확인해야 한다. 만약 HTTP 요청이라면, 브라우저는 도메인이 HSTS 목록에 있는지 확인 해야 한다. 이 목록은 사전에 로딩한 목록과 HSTS를 사용하도록 선택되어진 이전에 방문한 사이트 목록으로 구성되어 있으며, 두 사이트 목록 모두 브라우저에 저장된다. 요청된 HTTP 호스트가 HSTS 목록에 저장되어 있는 경우, HTTP 대신 HTTPS 버전의 URL로 요청이 이루어진다. 그렇기 때문에 브라우저에 http://yceffort.kr 를 입력해도 https://yceffort.kr 로 대신 보내진다.
다음 부터는, 브라우저는 서비스 워커가 요청을 처리할 수 있는지 확인해야 한다. 이 서비스 워커는 사용자가 오프라인 상태이고, 네트워크 연결이 없을 때 특히 중요하다. 서비스 워커는 비교적 최근에 나온 기능이다. (라고 하기엔 나온지는 꽤 되었지만) 서비스 워커는 오프라인에서도 웹 사이트를 사용할 수 있도록 네트워크 요청을 차단하고 캐시에서 처리할 수 있도록 도와준다.
서비스 워커는 페이지를 방문했을 때, 서비스 워커 등록 및 로컬 데이터 베이스에 URL 매핑을 기록할 수 있다. 서비스 워커가 설치되었는지 여부를 확인하는 것은 데이터베이스에서 이전에 탐색한 적이 있는 URL을 조회하는 것 만큼이나 간단하다. 지정된 URL에 서비스 워커가 있는 경우, 요청에 대한 응답을 처리할 수 있다. 브라우저에서 Navigation Preload를 사용할 수 있고, 사이트가 이 기능을 활용할 수 있는 경우, 브라우저는 초기 네비게이션 요청을 위해 네트워크를 동시에 참조한다. 이는 브라우저가 서비스 워커가 느려서 요청을 차단하지 않도록 하기 때문에 유용하다.
초기 요청을 처리한 서비스 워커가 없는 경우 (또는 Navigation Preload가 이미 사용 중인 경우) 브라우저는 네트워크 계층을 참조하기 시작한다.
브라우저는 네트워크 계층을 통해 캐시에 새로운 응답이 있는지 확인 한다. 일반적으로 이는 응답의 Cache-Control 헤더에 의해 정의된다. max-age 으로 캐시된 항목이 얼마나 유효한지 정의할 수 있으며, no-store로 저장되지 않는 캐시를 정의할 수도 있다. 그리고 물론, 브라우저가 네트워크 요청의 캐시에서 아무것도 확인할 수 없는 경우에는, 네트워크 요청이 필연적으로 필요하다. 이후에 약 캐시에 새로운 응답이 있을 경우, 페이지를 로드하기 위해 리턴된다. 리소스가 발견되었지만, 굳이 새로운 리소스가 필요하지 않은 경우, 브라우저는 이 요청을 조건부 재평가 요청 (conditional revalidation request) 으로 반환할 수 있다. 여기에는 브라우저가 캐시에 이미 있는 콘텐츠 버전을 서버에 알리는 If-Modified-Since If-None-Match 헤더가 포함된다. 서버는 응답 없이 HTTP 304를 반환하여 사본이 여전히 유효하다는 것을 알리거나, 새 버전의 리소스와 함께 200 응답을 반환하여 사본이 오래된 것임을 브라우저에 알릴 수도 있다.
호스트 및 특정 포트에 대해 이전에 설정되어있는 연결이 있는 경우, 새 연결을 설정하는 대신에 이전 연결을 계속해서 사용하게 된다. 이전 연결이 없는 경우에는, 브라우저는 네트워크 레이어를 참조하여 DNS 조회가 필요한지 파악한다. 이 작업에는 로컬 DNS 캐시를 살펴보는 작업도 포함되며, 캐시의 유통기한에 따라서 리모트 네임 서버도 참조할 수 있으며 (인터넷 서비스 공급자가 호스팅 하는 경우), 이 과정을 거치게 되면 브라우저가 연결 할 수 있는 올바른 IP 주소를 얻게 된다.
경우에 따라 브라우저가 접근할 도메인을 미리 예측할 수도 있으며, 예측 가능한 경우 이 도메인에 대한 연결이 준비 될 수도 있다. 링크 태그의 rel="preconnect"와 같은 리소스 힌트를 사용하여 이후에 연결을 할 도메인에 대해 브라우저에 힌트를 제공할 수 있다. 예를 들어, 구글에 검색 결과가 나왔다고 가정해보자. 구글 사이트 입장에서, 사용자는 최상단 몇개 정도의 사이트에 사용자가 접근할 예정이라고 가정할 수 있다. 이 경우 해당 도메인에 대한 링크를 준비해두면 나중에 해당 링크를 클릭할 때 DNS를 조회하고, 연결설정을 하는등의 비용을 지불할 필요가 없다.
이제 브라우저는 드디어 서버와 연결을 설정할 수 있으므로, 서버는 클라이언트로부터 송수신이 일어날 것을 알 수 있다. TLS를 사용하는 경우, 서버에서 제공하는 인증서의 유효성을 확인하기 위해 TLS 핸드셰이크를 수행해야 한다.
이 연결을 통과하는 첫 번째 요청은 바로 최상위 (루트) 페이지 요청이다. 일반적으로 이 파일은 서버에서 클라이언트로 제공되는 HTML 파일이다.
클라이언트로 데이터가 스트리밍 되면서, 이제 응답 데이터를 분석하게 된다. 먼저 브라우저는 응답의 헤더를 확인한다. HTTP 헤더는 HTTP 응답의 일부로 발송되는 일련의 key:value 쌍이다. 여기에서 응답 헤더가 Location Header 등을 활용해 리다이렉트를 지정하는 경우, 브라우저는 탐색 프로세스를 다시 시작하고, 여기서 언급한 첫번째 단계로 돌아간다.
서버 응답이 압축되어 있는 경우, 브라우저는 이 압축을 해제하려고 시도한다.
다음으로, 브라우저는 브라우저로 전송되는 파일의 MIME 유형을 파악하여 파일 로드 방법을 적절하게 해석할 수 있게 된다. 예를 들어 HTML이 파싱 및 렌더링 되는 동안 이미지 파일이 이미지 파일은 이미지 그 자체로 로드 된다. HTML 파서가 실행되면, 응답에서 다운로드 될 가능성이 있는 리소스의 URL을 검색하여, 브라우저에서 페이지를 렌더링하기 전에 미리 다운로드를 시작할 수 있다.
이 때, 요청된 URL이 브라우저 히스토리에 입력되어 브라우저의 앞, 뒤 버튼으로 탐색이 가능해진다.
여기까지 다룬 내용을 플로우 차트로 살펴보자.
페이지에는 이미지, 자바스크립트, 스타일 시트를 필요하여 페이지를 꾸미는데 필요한 다양한 하위 리소스가 있기 때문에 페이지는 계속해서 요청을 한다. 또한 백그라운드 이미지 (css), fetch() import() 또는 ajax 호출로 인해 시작된 리소스 등 호출이 필요한 다양한 리소스들이 존재한다. 이것들이 없다면 우리는 별다른 상호작용을 할 수 없는 평범한 페이지만 보게 될 것이다. 이렇게 요청한 리소스는 브라우저의 캐싱 정책에 의하여 부분적으로 영향을 받는다.
앞서 계속해서 언급했던 것 처럼, 브라우저는 네트워크 캐시를 관리하며 이는 이전에 다운로드 한 리소스를 재사용할 수 있게 도와준다. 이는 특히 로고나, 자바스크립트의 프레임워크와 같이 잘 변하지 않는 리소스에 매우 유용하다. 로컬에서 사용 가능한 캐시 리소스를 확인하고 재사용하는 것이, 네트워크 요청을 줄이는데 도움을 줄 수 있으므로 최대한 캐시를 활용해야 한다. 이는 결과적으로 번거로운 작업을 최소화 하여 페이지 로딩 시간을 단축하는데 많은 도움을 준다.
물론, 네트워크 캐시는 저장될 아이템의 개수와 저장 기간을 가지고 있다. 이 것은 웹 사이트가 이 문제를 컨트롤 할 수 없다는 것을 의미한다. 응답의 Cache-control 헤더는 브라우저의 캐시 로직을 제어 한다. 경우에 따라 캐시 하지 않는 것이 좋을 때도 있다. (Cache-Control: no-store) 어떤 경우에는 브라우저가 무기한 캐시하는 것이 좋을 수도 있다. (Cache-Control: immutable) 이 경우 캐시된 버전으로만 사용되므로, 동일한 URL의 리소스를 변경하는 대신, 다른 URL을 지정해줘서 다른 버전을 사용하도록 자연스럽게 유도하는 것이 좋다.
물론 네트워크 캐시가 브라우저가 할 수 있는 유일한 캐시는 아니다. 자바스크립트를 활용해서도 캐시를 구현할 수 있다. (프로그래밍 캐시) 위에서 언급했던 서비스 워커에서, 최상위 페이지에 대한 초기 리소스 요청은, 서비스워커가 이 요청을 인터셉터 한 다음 프로그래밍 캐시로 정의된 리소스를 대신 사용하게 할 수 잇다. 이는 웹 사이트가 캐시된 아이템을 언제 사용할 수 있는지 더 원활하게 제어할 수 있기 때문에 유용하다. 이러한 캐시는 origin을 기준으로 묶이며, 이는 곧 다른 도메인이 다른 도메인의 캐시로부터 분리된 제어 가능한 고유한 샌드박스 캐시 집합을 가지고 있음을 의미하기도 한다.
origin은 데이터를 샌드박스로 만들고 보호하는 방법을 정의내릴 수 있는 중요한 브라우저의 개념 중 하나다. 대부분의 경우 보안을 위해 브라우저는 same-origin policy를 적용한다. 한 origin이 다른 origin에 접근할 수 없다.
만약에 yceffort.kr이 yceffort1.kr이라는 다른 origin의 자바스크립트 파일을 요청하고자 한다면, 이는 cross-origin 리소스 요청이 되는 것이다. 이를 해결하기 위해서는, yceffort.kr을 위해 yceffort1.kr이 CORS 헤더를 지정해줘야 한다.
origin에 대한 정리는 여기에 잘 나와있습니다