◆ ESSAY
가비지 컬렉션은 모든 언어에서 굉장히 중요한 프로세스다. C와 같은 언어에서 수동으로 처리하고, 다른 언어에서는 이를 자동으로 처리한다. 이를 자바스크립트 내부에서는 어떻게 처리할까?
거의 모든 프로그래밍 언어의 메모리 라이프 사이클은 다음과 같이 작동한다.
차이 점은 이를 수행하는 방식 (사용하는 알고리즘)과 각 단계를 처리하는 방식(수동인지, 자동인지 여부)에 있다.
자바스크립트의 경우, 할당 및 해제는 자동으로 이루어 진다. 그렇다고 해서 개발자가 이에 대해 관심을 갖지 말라는 것은 아니다. 무한 루프, 잘못된 재귀처리, 콜백 지옥 등은 메모리 낭비를 이르켜 메모리 누수로 이어진다. 따라서 코딩을 잘해서 이러한 시나리오가 발생하지 않도록 하는 것이 중요하다.
자바스크립트의 경우, 새로운 변수가 선언되면 메모리에 공간이 할동 된다.
var bar = 'bar'
그리고 메모리가 더 이상 사용되지 않는다면, 변수 스코프 제한을 고려하여 메모리 공간 해제가 이루어진다.
하지만 어떻게 자바스크립트에서 더 이상 메모리가 사용되지 않는다는 것을 알까? 그것은 바로 가비지 콜렉를 통해서 이루어진다.
자바스크립트는 두개의 유명한 가비지 콜렉션 전략을 사용한다.
레퍼런스 카운팅은 파일, 소켓, 메모리 슬롯등 할당된 각 리소스를 가리키는 참조의 수를 계산하는 것이다.
메모리에 할당된 각 객체에 연결된 count 필드가 포함되어 있다고 생각해보자. 객체에 더 이상 가리키는 참조가 없을 때 자동으로 가비지 콜렉팅 된다.
var bar = {
name: 'bar',
}
bar = ''
위 예제에서 bar와 name이 존재한다. bar는 새로운 값을 받았기 때문에, name은 가비지 콜렉팅 된다.
좀 더 복잡한 아래 예제를 살펴보자.
var bar = {
name: 'bar',
}
var bar = 'foo'
function check() {
var bar = {}
var foo = {}
bar.name = foo
foo.name = bar
return true
}
check()
자바스크립트는 객체에 대한 참조 기반의 언어로, 이는 즉 객체 명이 메모리 내 인스턴스화 된 값을 가리키는 것을 의미한다. 이 예제에서는, 자식의 객채/변수는 부모가 자동으로 참조한다.
위 예제에서는 순환 참조를 만들고 있다. check함수내의 bar는 foo를 참조하고 있으며 그 반대 경우도 마찬가지다.
일반적으로 함수가 실행을 마치면 내부 요소는 가비지 컬렉팅이 된다. 그러나 이경우에는 객체가 여전히 서로 참조되고 있기 때문에 가비지 컬렉팅 되지 않는다.
여기에서 이제 자바스크립트의 두번째 작전인 mark-and-sweep 알고리즘이 동작한다.
이 알고리즘은 자바스크립트의 최상위 객체인 global(window)에 도달할 수 없는 객체를 찾는 방식으로 작동한다.
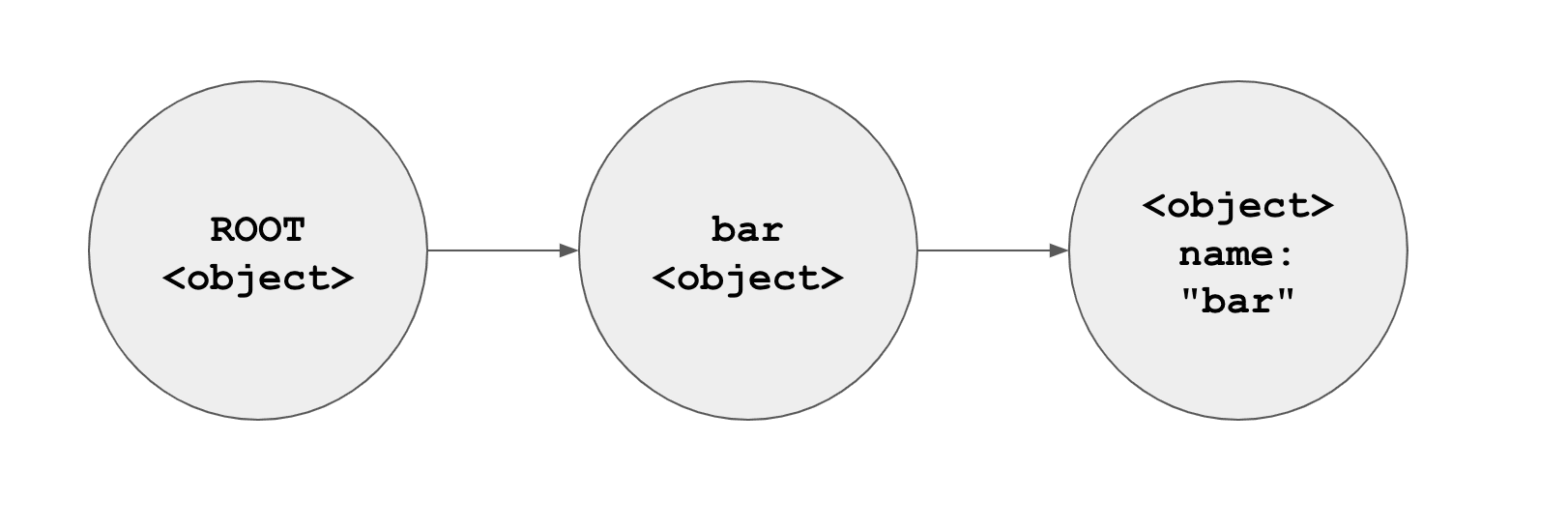
보시다시피, 자바스크립트는 name 객체를 최상위에서 쉽게 찾을 수 있다.
만약 다음 코드가 실행되면 어떻게 될까?
var bar = 'foo'
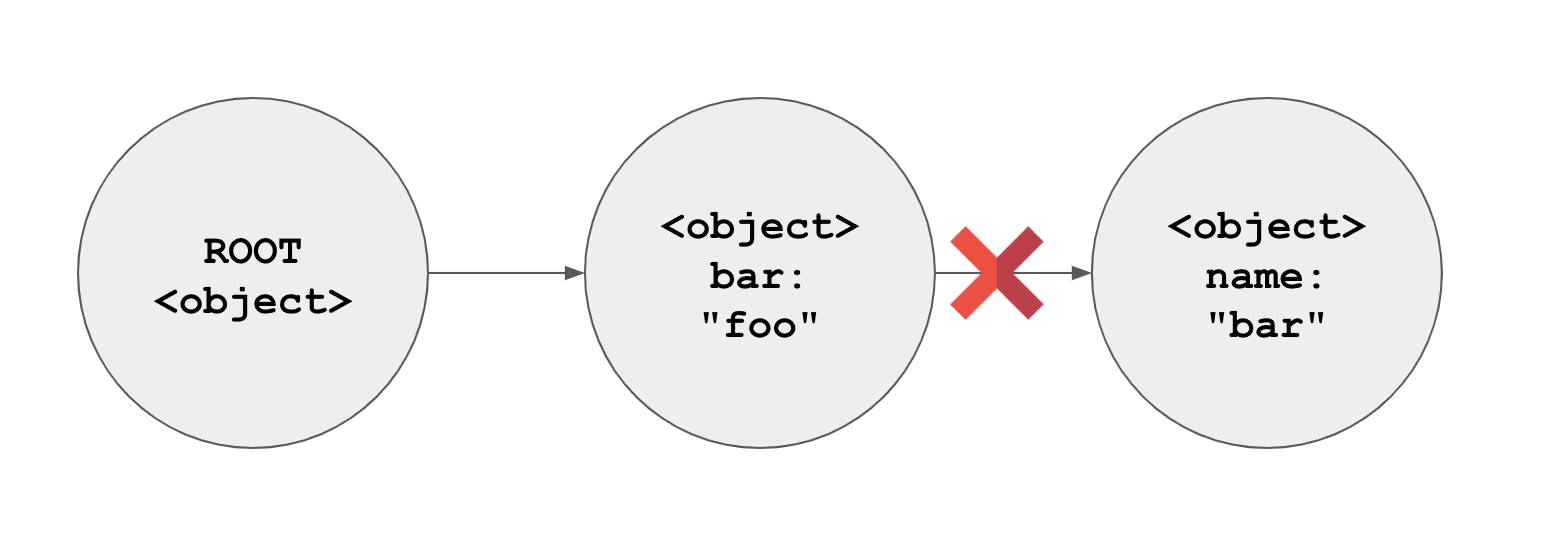
이제 더 이상 name은 root에서 접근할 수 없는 객체가 된다.
나머지 프로세스는 굉장히 직관적이다. 알고리즘은 루트에서 하단의 객체까지 각각 루트에서 접근할 수 있는 객체인지, 혹은 name처럼 더 이상 접근할 수 없는 객체인지를 별도로 표시해둔다.
이 과정은 자바스크립트의 GC만 알고 있는 몇몇 내부 조건을 통해 반복되고 있는데, 이는 대부분의 언어의 GC에서도 동일하게 동작한다.
Node.js의 가비지 콜렉션이 어떻게 동작하는지 이해하기 전에, heap과 stack에 대해서 알아두어야 한다.
heap은 참조유형에 해당하는 데이터들이 나타나는 곳이다. 여기서 참조 유형이라 함은 객체, string, 클로져 등을 의미한다.
따라서 자바스크립트에서 객체가 만들어지면, 객체는 heap에 위치하게 된다.
const myCat = new Cat('Joshua')
반면에, stack은 heap에서 생성된 객체에 대한 참조가 저장되는 곳이다. 예를 들어 함수의 argument는 stack에 존재하는 참조의 좋은 예다.
function Cat(name) {
this.name = name
}
그리고 힙은 new space와 old space로 나누어진다.
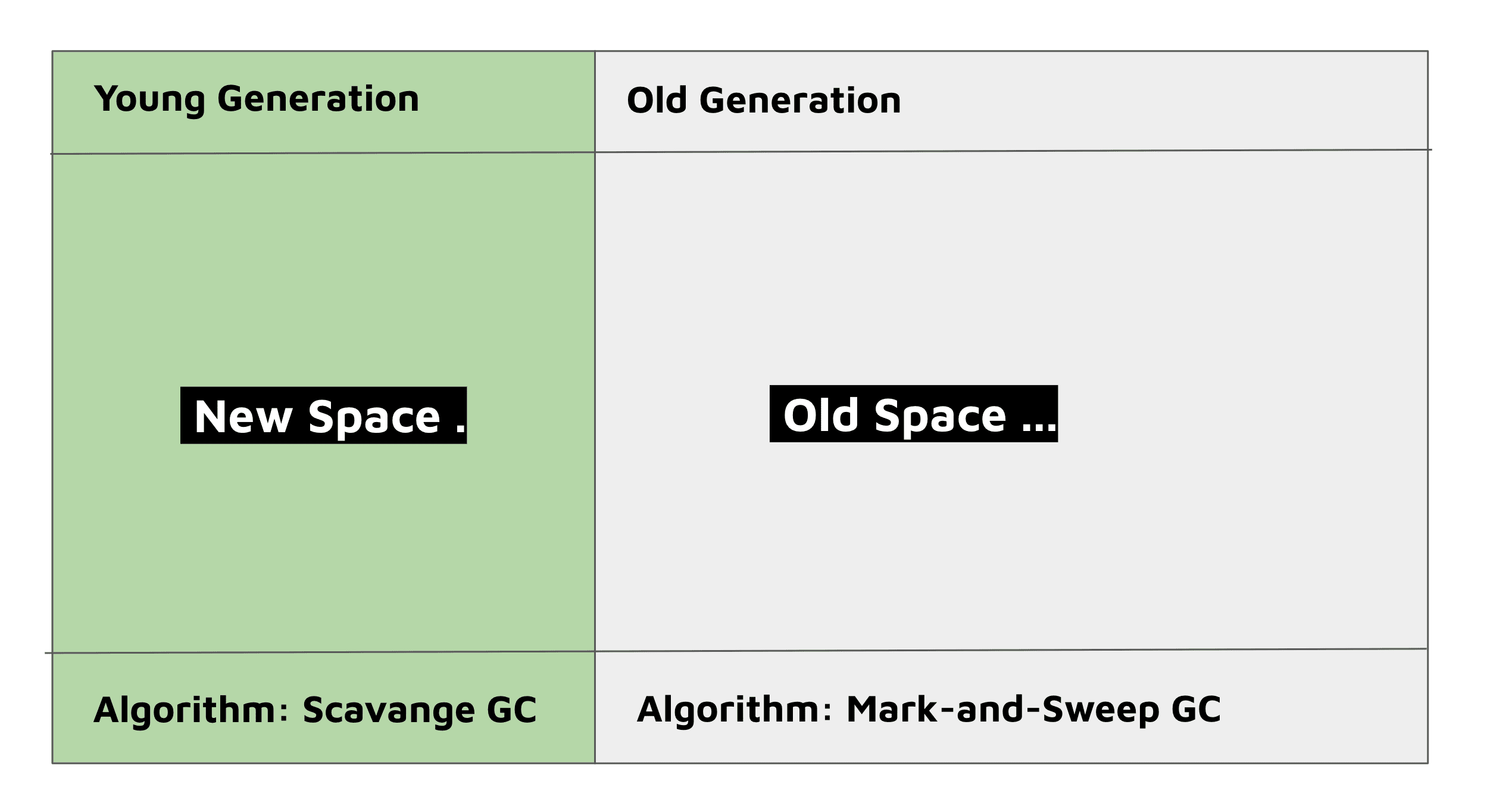
New space는 새로운 객체와 변수를 할당하는 메모리 영역이며, 이름 그대로 새로운 것들이기 때문에 GC 처리가 빠르다. 이름에서 알 수 있듯이, 이영역은 비교적 이르게 할당된 객체들이 존재한다.
Old space는 new space에서 수집되지 않는 객체들이 얼마 후에 이동하는 곳이다. 사이즈가 큰 객체나, V8로 컴파일된 코드와 같은 것들이 존재한다.
Node.js는 GC가 old space로 가지 않도록 최선을 다한다. 왜냐하면 old space는 GC를 하는데 더 많은 비용이 들기 때문이다. 따라서 전체 대상의 20% 정도만 old space로 이동한다.
Scavenge: 이 가비지 컬렉터는 실행될 때마다 메모리의 작은 부분을 청소하여 young generation을 처리한다. 매우 빠르다.Mark-and-sweep: 아까 언급했던 알고리즘으로, 느리지만 old generation에서 유용하게 동작할 수 있다.자바스크립트가 Nodejs 에서 메모리를 다루는 방법을 보는 좋은 예제는 아주 클래식한 메모리 누수 예제를 보는 것이다. 메모리 누수는 모든 GC전략이 루트 객체와의 연결을 잃어서 객체를 찾지 못할 때 발생한다. 그 외에도, 객체가 항상 다른 객체에 의해 참조되면서 동시에 크기가 커지는 경우에도 발생할 수 있다.
예를 들어 간단한 nodejs서버가 아래와 같이 있으며, 모든 요청에서 중요한 데이터를 저장하려 한다고 생각해보자.
const http = require('http')
const ml_Var = []
const server = http.createServer((req, res) => {
let chunk = JSON.stringify({url: req.url, now: new Date()})
ml_Var.push(chunk)
res.writeHead(200)
res.end(JSON.stringify(ml_Var))
})
const PORT = process.env.PORT || 3000
server.listen(PORT)
모든 요청에 대해서 json stringify로 리스트에 푸쉬한다고 가정해보자. ml_Var는 글로벌 변수 이기 때문에 서버가 종료될 때 까지 메모리에서 계속 존재할 수 있다. 이는 굉장히 위험한 지점이다.
특히 다른 개발자들이, 내가 볼 수 없는 지점에서 아이템을 추가할 수 있기 때문에, 이러한 객체는 애플리케이션에서 문제를 야기할 수 있다.
node --inspect index.js
Debugger listening on ws://127.0.0.1:9229/16ee16bb-f142-4836-b9cf-859799ce8ced
For help, see: https://nodejs.org/en/docs/inspector
이제 크롬에서 chrome://inspect 명령어로 살펴보면 아래와 같은 화면이 나온다.

remote target 섹션에 inspect링크가 있다. 이를 클릭하면, nodejs 애플리케이션의 세션을 볼 수 있는 화면이 뜬다. 로그, 소스, CPU 프로파일링 및 메모리 분석 등을 수행할 수 있다.
메모리 탭에서 Take snapshot을 크릭하면, 현재 실행중인 애플리케이션의 더미 스냅샷 프로필 (메모리 덤프)를 생성한다. 메모리 누수가 일어나기 전후의 메모리를 비교하는 것이 일단 목표다.
메모리 덤프를 가져오기에 앞서, 벤치 마킹을 돕기 위한 도구로 siege.js를 사용할 것이다. 이 라이브러리는 엔드포인트에 대해 수백 수천건의 요청을 실행하는 작업을 단순화 하는 node.js의 벤치마킹 도구다.
const siege = require('siege')
siege().on(3000).for(2000).times.get('/').attack()
3000포트에 대해서 /요청을 2000번 날릴 것이다.
GET:/
GET:/
GET:/
GET:/
GET:/GET:/GET:/GET:/ done:2000 200 OK: 2000 rps: 2721 response: 1ms(min) 24ms(max) 5ms(avg)
DevTool로 돌아가서 Take snap shot버튼을 누르자.
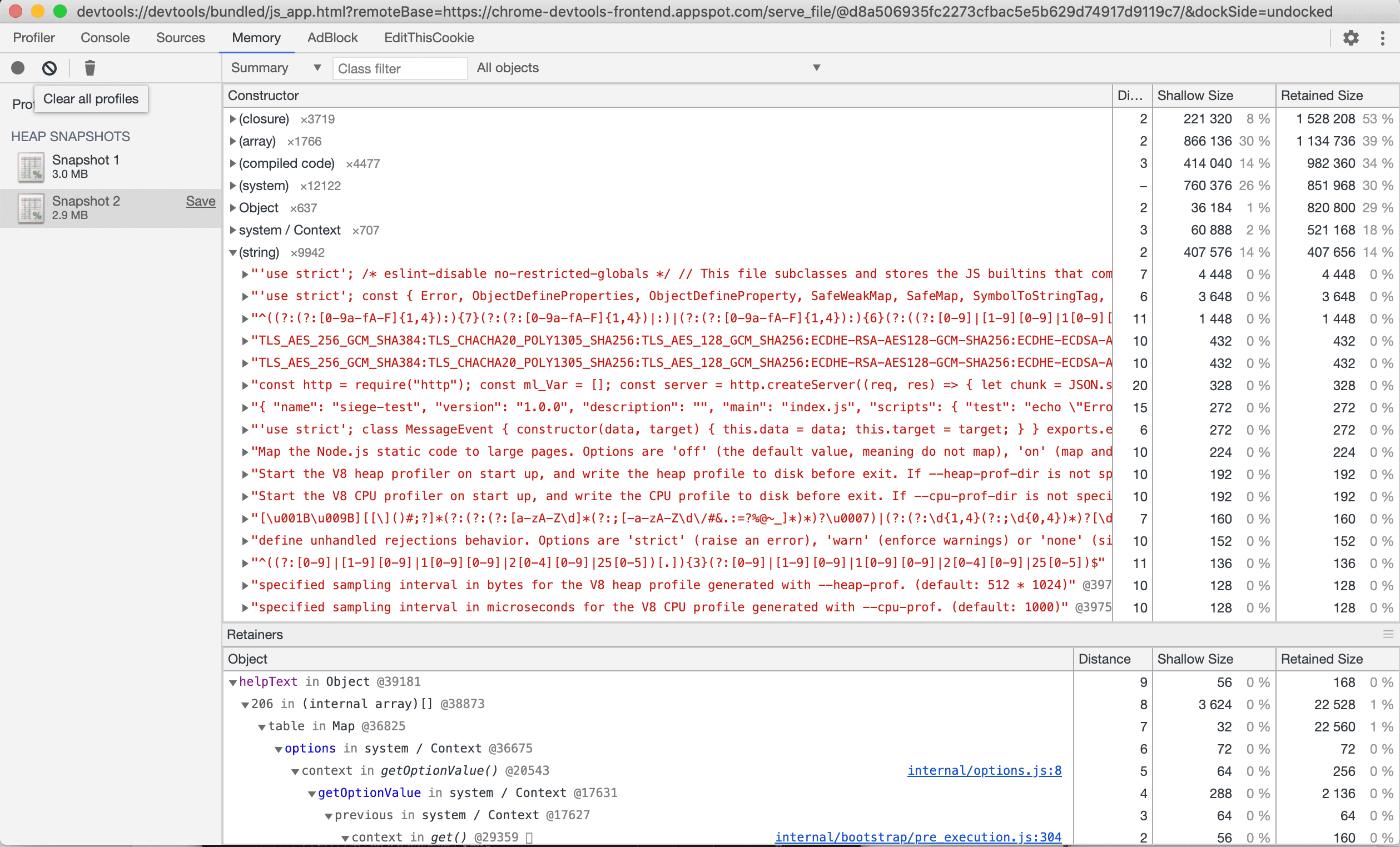
수 많은 string 들이 쌓인 것을 볼 수 있다. 실제 애플리케이션이었다면, 더 많은 양의 string 이 쌓여 있을 것이다. 따라서 이러한 메모리 누수를 조기에 발견하고 해결해야 할 것이다.


