- Published on
Tensorflow.js - 04. CNN
- Author

- Name
- yceffort
Table of Contents
Handwritten digit recognition with CNNs
이 튜토리얼에서는, Tensorflow.js의 CNN을 활용해 손글씨 숫자를 인식하는 모델을 만들어 볼 것입니다. 먼저, 손으로 쓴 수천개의 숫자 이미지와 이들의 라벨 (어떤 숫자인지)를 분류하는 훈련을 진행합니다. 그런 다음, 모델이 보지 못한 테스트 데이터를 사용하여 분류의 정확도를 평가합니다.
1. 들어가기전에
이 튜토리얼에서는, Tensorflow.js의 CNN을 활용해 손글씨 숫자를 인식하는 모델을 만들어 볼 것입니다. 먼저, 손으로 쓴 수천개의 숫자 이미지와 이들의 라벨 (어떤 숫자인지)를 분류하는 훈련을 진행합니다. 그런 다음, 모델이 보지 못한 테스트 데이터를 사용하여 분류의 정확도를 평가합니다.
입력으로 주어진 이미지에 카테고리(이미지에 나타나는 숫자)를 부여하기 위해 모델을 학습시키는 이 작업은 분류 작업으로 볼 수 있다. 우리는 최대한 많은 이미지와 정답을 입력해여 정확한 결과 값이 나오게 할 것입니다. 이를 Supervised Learning이라고 합니다.
만들어 볼 것
브라우저에서 Tensorflow.js를 활용해 모델을 훈련시키는 웹페이지를 만들어 볼 것입니다. 특정 크기의 흑백이미지에 나타나는 숫자를 분류하는 작업을 진행합니다. 이 작업에는
- 데이터 로딩
- 모델 아키텍쳐 정의
- 모델을 학습시키고 학습 성능을 실시간으로 측정
- 몇가지 예측을 통해 훈련된 모델을 평가
우리가 배울 것
- Tensorflow.js Layers API를 활용하여 Tensorflow.js syntax에 맞는 합성곱 모델을 만드는 법
- Tensorflow.js에서 분류 학습을 진행하는 법
tfjs-vis라이브러리를 활용해어 학습 과정을 실시간으로 모니터링 하는 법
학습 전에 준비해야 할 것
- 최신 버전의 크롬이나 es6 모듈을 지원하는 다른 모던 브라우저
- 로컬 머신에서 작동시킬 수 있는 텍스트 에디터 또는 웹에서 사용할 수 있는 Codepen이나 Glitch
- HTML, CSS, Javascript 그리고 Chrome Dev tool에 대한 지식 (혹은 선호하는 브라우저의 dev tool)
- 신경망에 대한 높은 수준의 이해. 학습이 필요하다면, 이 비디오들을 보기를 권장합니다. 3blue1brown Deep Learning in JS - Ashi Krishnan - JSConf EU 2018
2. Set up
HTML, Javascript 생성
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body></body>
</html>
데이터와 코드를 위한 자바스크립트 파일 생성
- HTML과 같은 레벨에,
data.js를 생성하고, 이 링크에 있는 파일 내용을 복사해서 넣어주세요. - 1번과 같은 레벨에
script.js를 생성하고, 아래 내용을 붙여 넣어주세요.
console.log('Hello TensorFlow')
여기에서 알려드린 코드에서는, 스크립트 태그로 로딩을 하고 있습니다. 많은 수의 자바스크립트 개발자들은 npm 으로 dependencies를 설치하고, 번들러로 프로젝트를 빌드하는 것을 선호합니다. 만약 할 수 있다면,
tensorflow.js와tfjs-vis를 npm으로 설치해보세요.
브라우저의 제약사항에 따라서, CORS 제한을 우회하기 위하여 로컬 브라우저에서 실행해야 할지도 모릅니다. Python SimpleServer나 Node Http server 두 가지 옵션이 있습니다. 아니면 Glitch와 같은 온라인 코딩 플랫폼을 이용하셔도 좋습니다.
저는 참고로 CodeSandbox를 사용합니다.
테스트 해보기
HTML과 javascript를 만들어 보았으므로, 테스트를 해볼 차례입니다. index.html을 브라우저에서 열고, devtools console을 열어보세요.
만약 모든게 잘 작동하고 있다면, 두개의 글로벌 변수가 생성되었을 것입니다. tf는 Tensorflow 라이브러리를 참조하고, tfvis는 tfjs-vis라이브러리를 참조합니다.
Hello Tensorflow라는 메시지를 보게 된다면, 다음 단계로 넘어갈 준비가 된 것입니다.
3. Load the Data
본 튜토리얼에서는 아래 이미지의 숫자를 인식하는 방법을 학습하기 위한 모델을 만들어 볼 것입니다. 여기에서 말하는 이미지는 28x28px 사이즈의 흑백이미지이며, MNIST라고 불리웁니다.

이 이미지들로 부터 만든 sprite file도 있습니다.
{kind=link}
data.js를 통해서 어떻게 데이터가 로딩되는지 확인해보세요. 이 튜토리얼을 한번 하고 나면, 스스로 데이터를 로딩하는 스크립트를 만들어보는 것도 좋습니다.
위 파일에는 MnistData 클래스가 있으며, 두 개의 public methods가 있습니다.
nextTrainBatch(batchSize): 무작위 배치 이미지와 라벨을 학습용 세트에서 리턴합니다.nextTestBatch(batchSize): 무작위 배치 이미지와 라벨을 테스트용 세트에서 리턴합니다.
MnistData 클래스는 또한 데이터를 섞고 정규화하는 중요한 일도 담당합니다.
여기에는 65,000개의 이미지가 있으며, 55,000개의 이미지는 학습용으로 사용하고, 10,000개의 이미지는 나중에 모델의 성능을 측정하기 위한 테스트용으로 둘 것입니다. 그리고 이러한 모든 것들이 브라우저에서 이루어집니다.
만약 Node.js가 익숙하시다면, 파일시스템에서 바로 이미지를 로딩해서, 픽셀데이터를 얻기 위한 native image processing을 활용해도 됩니다.
데이터를 로딩해보고, 테스트 해서 한번 제대로 되는지 확인해 봅시다.
import { MnistData } from './data.js'
async function showExamples(data) {
// Create a container in the visor
const surface = tfvis
.visor()
.surface({ name: 'Input Data Examples', tab: 'Input Data' })
// Get the examples
const examples = data.nextTestBatch(20)
const numExamples = examples.xs.shape[0]
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1])
})
const canvas = document.createElement('canvas')
canvas.width = 28
canvas.height = 28
canvas.style = 'margin: 4px;'
await tf.browser.toPixels(imageTensor, canvas)
surface.drawArea.appendChild(canvas)
imageTensor.dispose()
}
}
async function run() {
const data = new MnistData()
await data.load()
await showExamples(data)
}
document.addEventListener('DOMContentLoaded', run)
페이지를 새로고침하면, 몇 초 뒤에 이미지가 있는 패널이 나타날 것입니다.

4. 작업의 개념화
우리의 Input 데이터는 아래와 같을 것 입니다.
우리의 목표는 학습된 모델이 이미지 하나를 받으면, 그 이미지가 0~9사이의 숫자중 어떤 숫자에 가장 가까운지 각각 점수를 매겨서 예측하는 것입니다.
각각의 이이미지는 28*28 크기이며, color channel은 1입니다. (흑백) 따라서, 이미지의 형태를 데이터로 나타내면 [28, 28, 1]입니다.
하나의 이미지를 10개의 값으로 매핑하는 작업이라는점, 그리고 이미지의 데이터 형태를 명심하고 다음 섹션으로 넘어가겠습니다.
5. 모델 아키텍쳐 디자인
이 섹션에서는 모델 아키텍쳐를 묘사하는 코드를 작성할 것 입니다. 모델 아키텍쳐란 "어떤 함수를 사용하여 모델이 실행되는 과정에서 학습하게 할것인지" 또는 "답을 계산하기 위하여 어떤 알고리즘을 모델에서 사용할 것인지" 를 간지나게 말하는 것입니다.
머신러닝에서, 아키텍쳐(알고리즘)을 정의할 것이고, 학습 과정에서 알고리즘의 파라미터를 학습하게 할 것입니다.
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// 첫번째 covolutional 신경망에서는 input 이미지의 형태를 넣어둔다.
// 그 다음 합성곱 연산에 필요한 파라미터를 정의한다.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// MaxPooling Layer는 평균값을 내는 것이 아니라, 영역의 최대값을 활용해서 다운샘플링을 진행한다.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// conv2d와 maxpooling을 반복한다.
// 이 convolution에서 더 많은 필터가 있다는 것을 기억하자.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// 2D형태의 필터를 1D 벡터 형태로 평평하게 하여, 마지막 layer에 인풋으로 넣을 수 있도록 한다.
// 이는 고차원의 데이터를 마지막 분류 레이어에 전달할 때 하는 일반적인 과정이다.
model.add(tf.layers.flatten());
// 마지막 레이어는 10개의 값이 나오게 된다.
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// optimizer, loss function, accuracy meetric을 고르고, 컴파일 후에 모델을 리턴한다.
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
합성곱
model.add(
tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling',
}),
)
여기에서는 sequential 모델을 사용한다.
우리는 dense layer 대시엔 conv2d layer를 사용한다. 여기에서는 합성곱이 어떻게 작동하는지까지 자세하게 설명할 수 없지만, 어떻게 작동하는지 설명해주는 좋은 아티클이 있습니다.
conv2d object를 구성하는 argument 들에 대해 하나씩 알아봅시다.
inputShape: 모델의 첫번째 레이어에 들어가는 데이터의 형태입니다. 이번 예제에서는, 28*28크기의 MNIST 흑백이미지를 사용하고 있습니다. 즉[row, column, depth],[28, 28, 1]로 넣을 수 있습니다. 가로 세로 각 28 픽셀이 자리잡고 있으며, color channel은 흑백이미지 이므로 1밖에 없습니다. 한가지 알아둬야 할 것은, input shape안에 batch size를 정의하지 않았다는 것입니다.kernelSize: input data에 적용할 합성곱 필터의 윈도우 크기 입니다. 여기에서는 5로 설정했기 때문에, 정사각형 형태의 5x5 합성곱 윈도우가 만들어집니다.filters: kernelSize에서 적용한 filter window의 개수입니다. 여기에서는 8로 설정했습니다.strides: 슬라이딩 윈도우의 step size 입니다. 이미지 위로 이동할 때마다 이동할 픽셀의 수를 의미합니다. 여기서 우리는 1을 지정하는데, 이는 필터가 1픽셀 단위로 이미지 위에서 이동한다는 것을 의미합니다.activation: 합성곱 연산이 끝난뒤에 적용할 활성화 함수입니다. 여기에서는 머신러닝 모델에서 가장 흔히 사용되는 ReLU 적용합니다.kernelInitializer: 랜덤하게 가중치 값을 초기화 하는 메서드로, 다이나믹 학습을 위해 굉장히 중요한 부분이다. 여기에서는 자세한 내용을 다루지는 않을 것이지만, 일반적으로는 (그리고 여기에서는)VarianceScaling를 쓴다. 참고
dense layer 만으로도 이미지 분류기를 만들 수 있지만, 대부분의 이미지 기반 작업에서는 합성곱 레이어가 더 효과적이라는 것이 증명되었습니다.
데이터를 평평하게 만들기
model.add(tf.layers.flatten())
이미지는 보통 고차원의 데이터라서, 합성곱 작업을 하게되면 데이터의 크기가 커지는 경향이 있다. 이를 마지막 분류 레이어에 넣기 전에, 하나의 단순한 긴 array로 평평하게 만들 필요가 있다. Dense layer(우리가 마지막 레이어라고 말하는 것)은 tensor1d만 받는데, 이는 일반적인 분류 작업에서 보통 이렇게 진행한다.
평평해진 레이어에는 가중치가 없습니다. 단순히 입력된 값을 긴 배열로 풀기만 하면 됩니다.
확률분포를 계산하기
const NUM_OUTPUT_CLASSES = 10
model.add(
tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax',
}),
)
여기에서는 optimizer, loss function 그리고 우리가 추적하고자 하는 지표들을 모델에 입력하고 컴파일합니다.
첫번째 튜토리얼과는 다르게, 손실 함수로 categoricalCrossentropy를 사용했습니다. 이름이 암시하듯이, 모델의 최종 결과 값이 확률 분포일 때 사용합니다. categoricalCrossentropy는 모델의 마지막 층에서 만들어진 확률분포와, 우리가 주어준 진짜 라벨에서 주어진 확률분포 사이의 오류를 측정합니다.
예를 들어, 결과값이 7인 이미지에 대해서는 결과가 아래와 같이 나올 것입니다.
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| True label | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| Prediction | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
Categorical cross entropy는 실제 주어진 label과 비교했을 때 얼마나 비슷한지를 예측하는 숫자를 만들어냅니다.
여기에서 주어진 데이터에서는, 이른바 one-hot encoding이라고 불리우는, 분류 문제에서 흔히 쓰이는 기법을 사용했습니다. 각각 클래스는 주어진 예시들에 대해 그것과 관련된 확률을 가지고 있습니다. 우리가 정확히 어떤 것인지 예측해야 할때, 그것이 맞다면 1을, 아니라면 0으로 나타낼 수 있습니다. one-hot encoding에 대한 자세한 내용은 여기를 참조하세요.
우리가 모니터링할 다른 지표는 분류 문제에 대한 정확성입니다. 이는 모든 예측 중 정확하게 예측한 비율을 의미합니다.
6. 모델 훈련하기
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc']
const container = {
name: 'Model Training',
styles: { height: '1000px' },
}
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics)
const BATCH_SIZE = 512
const TRAIN_DATA_SIZE = 5500
const TEST_DATA_SIZE = 1000
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE)
return [d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]), d.labels]
})
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE)
return [d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]), d.labels]
})
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks,
})
}
const model = getModel()
tfvis.show.modelSummary({ name: 'Model Architecture' }, model)
await train(model, data)
새로고침을 하고 몇 초뒤에, 아래와 같이 훈련과정이 담긴 화면이 나올 것입니다.
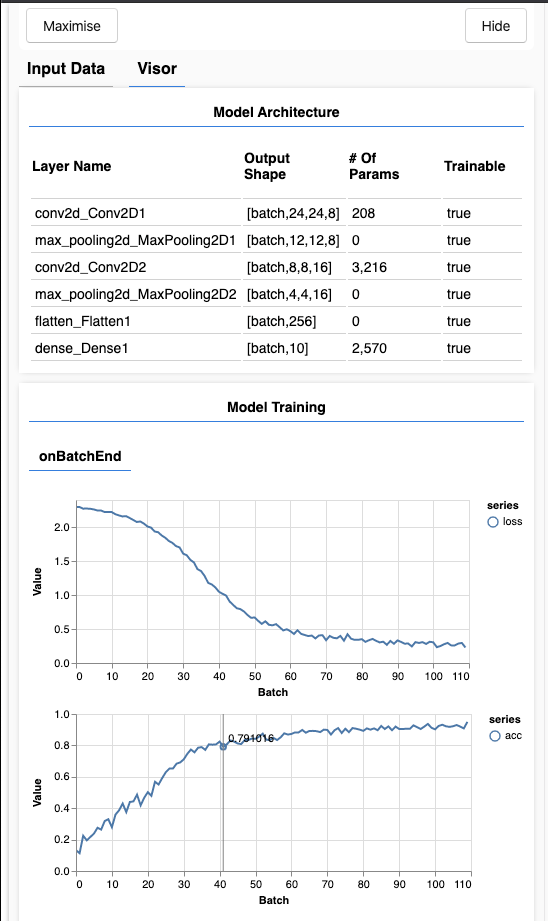
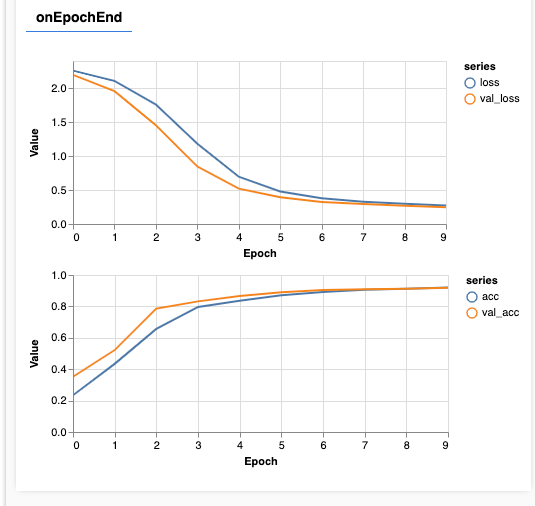
조금 자세히 살펴봅시다.
메트릭 모니터링
const metrics = ['loss', 'val_loss', 'acc', 'val_acc']
여기에서 우리는 어떤 요소들을 모니터링 할 것이지 선언합니다. 여기에서는 학습 세트의 loss, 정확성 뿐만 아니라 validation set (val_loss, val_acc)의 loss와 정확성을 모니터링합니다. 아래에서 좀더 자세히 알아봅시다.
알아두기: Layers API를 사용하는 경우, Loss는 매 배치마다 계산되고, 정확도는 전체 데이터셋의 epoch 마다 계산됩니다.
데이터를 tensor로 변환하기
const BATCH_SIZE = 512
const TRAIN_DATA_SIZE = 5500
const TEST_DATA_SIZE = 1000
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE)
return [d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]), d.labels]
})
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE)
return [d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]), d.labels]
})
여기에서 우리는 두개의 데이터셋을 만들었는데, 하나는 학습 과정에서 쓰이는 학습세트고, 다른 하나는 validation 과정에서 쓰이는 세트입니다. 이러한 validation set는 학습과정에서 모델에게 절대 노출되지 않습니다.
우리가 제공한 데이터 클레스는, 이미지 데이터로부터 텐서를 쉽게 얻을 수 있게 만들어줍니다. 그러나 우리는 텐서를 모델에 넘기기전에, [num_examples, image_width, image_height, channels] 형태로 다시 만들어 냅니다. 각각의 데이터셋에는 X input, Y label이 존재합니다.
trainDataSize는 5500으로, testDataSize는 1000으로 설정되어 있는데, 이는 테스트를 조금더 빠르게 하기 위함입니다. 이 튜토리얼이 끝난 뒤에는 각각 55000과 10000으로 설정해 보시길 바랍니다. 학습은 조금더 오래 걸리겠지만, 여러머신에서 동작하는 브라우저에서는 동작할 것입니다.
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks,
})
model.fit을 학습 루프 시작과정에서 호출합니다. 또한 validationData 속성을 전달하여, 각 학습 이후에 모델이 자신을 테스트하기 위해 사용해야 하는 데이터를 명시합니다. (학습 과정에서는 사용되지 않음.)
validation 데이터를 학습과정에서 넘기지 않는 다는 것은, 학습 과정이 overfitting 되는 것을 방지하고, 이전에 봤던 데이터로 일반화 시키지 않는 다는 것을 의미합니다.
7. 모델 평가하기
유효성 검사의 정확도는 이전에 학습한 모델이 보지 못한 데이터에 대해, 우리가 만든 모델이 얼마나 잘 예측할 지에 대한 추정치를 제공합니다. 또한 다양한 레이어에 걸쳐 더 자세한 성능 분석을 할수도 있습니다.
tfjs-vis 이러한 작업을 도와줄 수 있는 몇가지 메서드 들이 있습니다.
const classNames = [
'Zero',
'One',
'Two',
'Three',
'Four',
'Five',
'Six',
'Seven',
'Eight',
'Nine',
]
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28
const IMAGE_HEIGHT = 28
const testData = data.nextTestBatch(testDataSize)
const testxs = testData.xs.reshape([
testDataSize,
IMAGE_WIDTH,
IMAGE_HEIGHT,
1,
])
const labels = testData.labels.argMax([-1])
const preds = model.predict(testxs).argMax([-1])
testxs.dispose()
return [preds, labels]
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data)
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds)
const container = { name: 'Accuracy', tab: 'Evaluation' }
tfvis.show.perClassAccuracy(container, classAccuracy, classNames)
labels.dispose()
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data)
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds)
const container = { name: 'Confusion Matrix', tab: 'Evaluation' }
tfvis.render.confusionMatrix(
container,
{ values: confusionMatrix },
classNames,
)
labels.dispose()
}
위의 코드들이 어떤 일을 할까요?
- 예측하기
- 정확도 계산
- 메트릭 정보 제공
좀 더 자세히 살펴 봅시다.
예측하기
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28
const IMAGE_HEIGHT = 28
const testData = data.nextTestBatch(testDataSize)
const testxs = testData.xs.reshape([
testDataSize,
IMAGE_WIDTH,
IMAGE_HEIGHT,
1,
])
const labels = testData.labels.argMax([-1])
const preds = model.predict(testxs).argMax([-1])
testxs.dispose()
return [preds, labels]
}
먼저 우리는 몇 가지 예측을 할 필요가 있습니다. 여기에서는, 500개의 이미지를 골라서 어떤 숫자인지 예측합니다. (나중에 더 많은 이미지를 대상으로 예측해보세요)
argmax 함수가 예측한 확률 중에서 가장 높은 확률을 보인 것을 반환합니다. 모델의 결과에는 각 숫자에 대한 확률이 있다는 것을 명심하세요. 여기에서는 가장 확률니 높게 나온 숫자를 받아서 예측에 사용합니다.
또한 여기에서 500개의 이미지를 한번에 예측한다는 것을 알 수 있을 겁니다. 이것은 Tensorflow.js가 제공하는 vectorization의 강력함을 엿볼 수 있는 대목입니다.
알아두기: 여기에서는 어떤 probability threshold 도 사용하지 않았습니다. 우리는 우리는 상관관계가 낫다 하더라도, 일단 그냥 제일 높은 확률이 나온 값을 취했습니다. 최소 임계점 확률을 설정해 놓은 뒤에, 확률이 이 밑으로 떨어지면 '숫자를 찾지 못함' 이라는 결과 값을 리턴하는 것도 흥미로울 것 입니다.
doPrecitions는 일단 학습된 모델이 어떻게 예측하는지를 보여줍니다. 그러나 완전히 새로운 데이터에 대해서는 예측만 하게 되므로 결과 값을 알 수 없을 것입니다.
각 숫자당 정확도
async function showAccuracy() {
const [preds, labels] = doPrediction()
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds)
const container = { name: 'Accuracy', tab: 'Evaluation' }
tfvis.show.perClassAccuracy(container, classAccuracy, classNames)
labels.dispose()
}
일련의 예측값과 결과값으로 우리는 얼마나 정확하게 예측한지를 알 수 있습니다.
Confusion Matrix
async function showConfusion() {
const [preds, labels] = doPrediction()
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds)
const container = { name: 'Confusion Matrix', tab: 'Evaluation' }
tfvis.show.confusionMatrix(container, confusionMatrix, classNames)
labels.dispose()
}
confusion matrix는 클래스(숫자)당 확률을 보여주는 것과 비슷하지만, 오분류 패턴을 더욱 세분화 해서 보여줍니다. 이것은 모델이 특정 어떤 숫자(데이터) 에 대해 혼란스러워했는지 알려줍니다.
결과
await showAccuracy(model, data)
await showConfusion(model, data)
이제 아래와 같은 값이 나타날 것입니다.
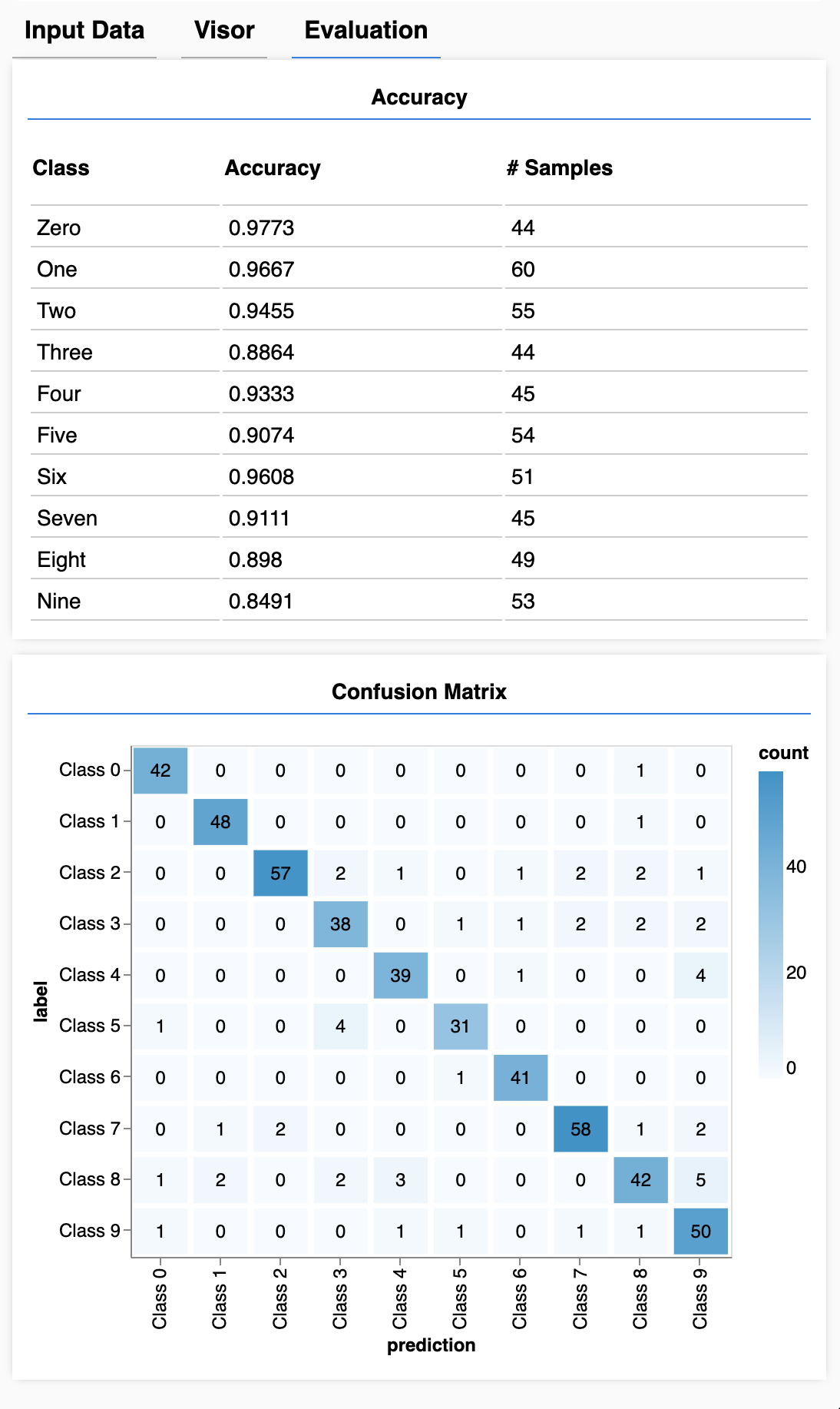
음, 0과 1을 잘 예측하고 3과 8을 헷갈려 하네요.
8. 정리
입력된 데이터에 대해 어떤 카테고리인지 예측하는 것을 분류 작업 (classification task)라고 한다.
분류 작업은 각 결과(label)별로 데이터를 필요로 한다.
- label을 포함한 데이터를 보여주는 일반적인 방식에는 one-hot encoding이 있다.
데이터 준비
- 모델이 학습 중에 보지 못한 데이터를 제공하는 것이 중요하다. 이를 validation set이라고 한다.
나만의 모델을 만들고 실행하기
- 합성곱 모델은 이미지 관련 작업을 할 때 유용하다.
- 분류 문제에서는 보통 손실 함수로 categorical cross entropy를 사용한다.
- 학습 과정을 모니터링 함으로써 손실이 점점 줄어드는지, 정확도가 올라가는지 확인해야 한다.
모델 평가하기
- 초기에 해결하고자 하는 문제를 잘 헤쳐나가는지를 파악하기 위해, 어떤 식으로 모델을 평가할지 미리 결정해 둬야 한다.
- 각 클래스별 정확도와 confusion matrix는 전반적인 정확도를 보는 것보다 모델을 세분화해서 성능을 보여주므로 유용하다.