- Published on
Pytorch 07) - Convolutional Neural Network (2)
- Author

- Name
- yceffort
Pytorch - 07) Convolutional Neural Network (2)
이번에는 코드로 구현해보자.
class LeNet(nn.Module):
def __init__(self):
super().__init__()
# 흑백이라 1채널, 20개 특징 추출, filter 크기, stride 1
self.conv1 = nn.Conv2d(1, 20, 5, 1)
# 전에서 20개
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
# 0.5 가 권장 할 만하대
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
# flatten
x = x.view(-1, 4 * 4 * 50)
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = self.fc2(x)
return x
먼저 첫번째 conv1애서는 1개의 필터, 20개의 특징을 추출 해 낼 것이다. 필터는 5x5 크기로, 이미지가 그리 크지 않으므로 stride는 1로 할것이다.
두번 conv2는 입력값이 20이고 (이전 conv의 ouput), 50개의 특징을 같은 크기와 stride로 찾는다.
그리고 마지막에는 fully conncted layer를 linear로 취한다. 여기서 주목할 것은 첫번째 fc의 input 값이다. 필터의 크기가 5x5 이기 때문에, 5x5필터는 width 와 heigt를 각각 4씩 줄인다.
- 1x1 필터: 원래크기 유지
- 2x2 필터: 크기 1 감소
- 3x3 필터: 크기 2 감소
- 4x4 필터: 크기 3 감소
- 5x5 필터: 크기 4 감소
따라서 각 conv layer를 거칠 때마다 크기가 4씩 줄어들게 된다.
그리고 max_pool2d를 2,2 크기로 사용할 것이므로 크기는 절반으로 줄어들게 된다. 요약하자면 다음과 같다.
| input | conv1 | pool1 | conv2 | pool2 |
|---|---|---|---|---|
| 28 | 24 | 12 | 8 | 4 |
4x4 크기의 이미지가, 50개의 특징으로 나오게 되므로, fully connected 의 input은 이 된다. 그리고 이를 500개의 output 으로 만들 것이다. 그리고 과적합을 방지하기 위하여, dropout을 0.5비율로 적용했다. 마지막 fc에서는, 10개의 숫자를 판별해야 하므로 500, 10을 적용했다.
활성화 함수로는 relu를 사용하였고, fully connected로 넘기기 위해, 평탄화를 작업(view적용)을 한다. 몇줄이 생길지는 모르겠지만, 암튼 row를 를 맞추기 위하여 .view(-1, 4*4*50) 을 적용했다. fc1을 쓰고, 그 사이에 dropout을 하고, 마지막에는 relu없이 값을 내보낸다.
이 것이 바로 LeNet이다.

training
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
epochs = 12
running_loss_history = []
running_correct_history = []
validation_running_loss_history = []
validation_running_correct_history = []
for e in range(epochs):
running_loss = 0.0
running_correct = 0.0
validation_running_loss = 0.0
validation_running_correct = 0.0
for inputs, labels in training_loader:
inputs = inputs.to(device)
labels = labels.to(device)
# inputs = inputs.view(inputs.shape[0], -1)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_correct += torch.sum(preds == labels.data)
running_loss += loss.item()
else:
# 훈련팔 필요가 없으므로 메모리 절약
with torch.no_grad():
for val_input, val_label in validation_loader:
val_input = val_input.to(device)
val_label = val_label.to(device)
# val_input = val_input.view(val_input.shape[0], -1)
val_outputs = model(val_input)
val_loss = criterion(val_outputs, val_label)
_, val_preds = torch.max(val_outputs, 1)
validation_running_loss += val_loss.item()
validation_running_correct += torch.sum(val_preds == val_label.data)
epoch_loss = running_loss / len(training_loader)
epoch_acc = running_correct.float() / len(training_loader)
running_loss_history.append(epoch_loss)
running_correct_history.append(epoch_acc)
val_epoch_loss = validation_running_loss / len(validation_loader)
val_epoch_acc = validation_running_correct.float() / len(validation_loader)
validation_running_loss_history.append(val_epoch_loss)
validation_running_correct_history.append(val_epoch_acc)
print("===================================================")
print("epoch: ", e + 1)
print("training loss: {:.5f}, acc: {:5f}".format(epoch_loss, epoch_acc))
print("validation loss: {:.5f}, acc: {:5f}".format(val_epoch_loss, val_epoch_acc))
===================================================
epoch: 1
training loss: 0.57984, acc: 84.566666
validation loss: 0.17183, acc: 95.019997
===================================================
epoch: 2
training loss: 0.14266, acc: 95.785004
validation loss: 0.10837, acc: 96.729996
===================================================
epoch: 3
training loss: 0.09881, acc: 97.026672
validation loss: 0.07965, acc: 97.529999
===================================================
epoch: 4
training loss: 0.07957, acc: 97.633339
validation loss: 0.06295, acc: 97.970001
===================================================
epoch: 5
training loss: 0.06528, acc: 97.988335
validation loss: 0.05194, acc: 98.389999
===================================================
epoch: 6
training loss: 0.05605, acc: 98.290001
validation loss: 0.04634, acc: 98.419998
===================================================
epoch: 7
training loss: 0.05048, acc: 98.465004
validation loss: 0.04152, acc: 98.779999
===================================================
epoch: 8
training loss: 0.04411, acc: 98.653336
validation loss: 0.03743, acc: 98.820000
===================================================
epoch: 9
training loss: 0.03852, acc: 98.820000
validation loss: 0.03573, acc: 98.869995
===================================================
epoch: 10
training loss: 0.03615, acc: 98.881668
validation loss: 0.03582, acc: 98.839996
===================================================
epoch: 11
training loss: 0.03363, acc: 98.976669
validation loss: 0.03422, acc: 98.820000
===================================================
epoch: 12
training loss: 0.03024, acc: 99.063339
validation loss: 0.03219, acc: 98.879997
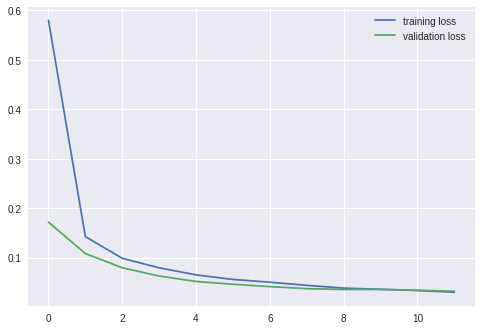
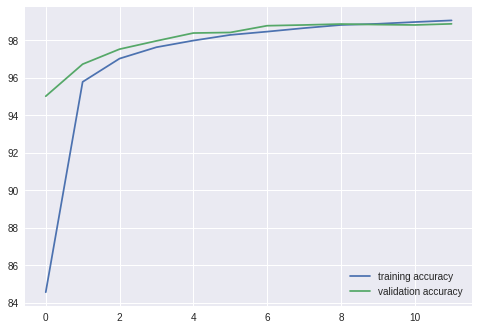

약 99% 의 정확도로 이미지를 분류하였으며, 이전에 제대로 구별하지 못한 이미지도 제대로 구별해 내었다.