- Published on
Pytorch (3) - 합성곱신경망 (CNN - Convolutional neural Network)
- Author

- Name
- yceffort
합성곱신경망(CNN - Convolutaional Neural Network, 이하 CNN)은 말그대로, 합성곱 연산을 사용하는 인공신경망의 한 종류다. Convolution을 활용하면 3차원 데이터의 공간적 정보를 유지한 상태로 다음 레이어로 보내는 것이 가능하다.
CN N역시 입력층, 중간층, 출력층으로 구성되어 있으며 각 층은 다시 노드로 이루어져 있으며, 층과 층사이에만 노드간 결합이 있다는 것도 다중 퍼셉트론과 동일하다. 마찬가지로, 지도학습 알고리즘 이기 때문에 설명변수와 목적변수가 들어 있다.
다만 차이가 있다면, 중간층이 합성곱층, 풀링충, 전결합충으로 구성되어 있다는 것이 다르다.
1. 합성곱층
가장 첫번째로 배치되는 레이어다. 입력 데이터에 필터를 적용해서 데이터에서 특징값을 추출한다.
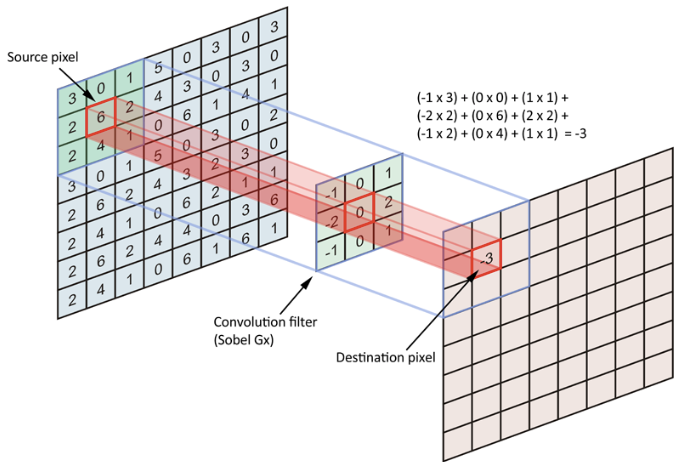
첫번째 그림이 입력층이고, 가운데가 필터다. 가중치를 가진 필터를 입력데이터의 각 위치마다 적용하고, 각 노드의 값과 가중치의 곱셈합을 구하는 방식으로 특징값을 추출한다. 그리고 그 결과를 맵형태로 다음 레이어에 전달하는 것이다.
2. 풀링층
풀링층은 앞서 전달 받은 합성곱층의 데이터에서 일정영역마다 최댓값 (평균값을 구하는 경우도 있다) 을 남긴다. 이런 방법을 활용하여 중요한 특징만을 남기게 된다.

이렇게 되면, 데이터의 기존 크기에 비해서 특징이 추출된 맵의 개수가 적어지게 된다. 이 개수를 입력 데이터의 크기에 맞춰 유지하기 위해 입력 데이터에 패딩을 적용하기도 한다. CNN에서는 입력 데이터의 패딩영역을 0으로 채우는 제로 패딩을 주로 사용한다.

학습과정에서 이 방식으로 순전파와 역전파를 반복하며, Convolutional 필터의 가중치를 최적화 하는 방식으로 모형을 학습하게 된다.

https://cs231n.github.io/assets/conv-demo/index.html
손글씨 이미지 분류하기
일단 데이터 전처리 과정까지는 똑같다.
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.datasets import load_digits
from sklearn import datasets, model_selection
from matplotlib import pyplot as plt
from matplotlib import cm
import pandas as pd
%matplotlib inline
import urllib
from scipy.io import loadmat
mnist_alternative_url = "https://github.com/amplab/datascience-sp14/raw/master/lab7/mldata/mnist-original.mat"
mnist_path = "./mnist-original.mat"
response = urllib.request.urlopen(mnist_alternative_url)
with open(mnist_path, "wb") as f:
content = response.read()
f.write(content)
mnist_raw = loadmat(mnist_path)
mnist = {
"data": mnist_raw["data"].T,
"target": mnist_raw["label"][0],
"COL_NAMES": ["label", "data"],
"DESCR": "mldata.org dataset: mnist-original",
}
print("Success!")
mnist_data = mnist['data'] / 255
mnist_label = mnist['target']
train_size = 50000
test_size = 500
train_X, test_X, train_Y, test_Y = model_selection.train_test_split(mnist_data,
mnist_label,
train_size=train_size,
test_size=test_size
)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
이제 달라진다. 기존에는 1차원 배열로 변환해서 flatten 구별했지만, 이제는 2차원 배열로 만들어서 작업을 한다.
# 1차원 배열을 28 * 28 이차원 배열로 만듦
train_X = train_X.reshape((len(train_X), 1, 28, 28))
test_X = test_X.reshape((len(test_X), 1, 28, 28))
train_X = torch.from_numpy(train_X).float().to(device)
train_Y = torch.from_numpy(train_Y).long().to(device)
test_X = torch.from_numpy(test_X).float().to(device)
test_Y = torch.from_numpy(test_Y).long().to(device)
print(train_X.shape)
print(train_Y.shape)
# 설명변수와 목적변수 텐서를 합침
train = TensorDataset(train_X, train_Y)
# 텐서의 첫 번째 데이터를 확인
print(train[0])
# 미니배치 분할
train_loader = DataLoader(train, batch_size=100, shuffle=True)
그리고 cuda를 사용해서 작업했다. 확실히 그냥 CPU로 작업하게 되면 엄청 느리다. 다음은 신경망 이다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 합성곱층
# 입력채널 수(1), 출력채널수(6), 필터크기(5)
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 전결합층
self.fc1 = nn.Linear(256, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
# 풀링층
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, 256)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x)
model = Net()
model.cuda()
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=256, out_features=64, bias=True)
(fc2): Linear(in_features=64, out_features=10, bias=True)
)
일단 필터 사이즈는 5,5 로 구성했고, stride (필터의 이동) 은 한칸씩으로 구성했다.
Convolution Layer 크기
Convolution Layer의 출력 데이터 크기는 아래와 같이 산정한다.
- 입력 데이터 높이: H
- 입력 데이터 폭: W
- 필터 높이: FH
- 필터 폭: FW
- stride 크기: S
- 패딩사이즈: P
주의 할 점은 여기에서 이 숫자들은 자연수가 되어야 한다는 것이다. 또한 Covolutional layer 다음에 pooling layer가 온다면 pooling 크기의 배수가 되어야 한다.
1번째 Convolutional Layer 부터 살펴보자. 입력크기가 1 (그레이스케일 이미지의 채널수는 1), 출력크기는 6, 필터크기는 5다. 2번째 레이어는 입력크기가 6 (첫번째에서 6의 크기로 출렸했으므로) , 출력크기가 16, 필터크기는 5다.
출력크기 구하기
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
total_loss = 0
for train_x, train_y in train_loader:
train_x, train_y = Variable(train_x), Variable(train_y)
optimizer.zero_grad()
output = model(train_x)
loss = criterion(output, train_y)
loss.backward()
optimizer.step()
total_loss += loss.data.item()
if (epoch+1) % 10 == 0:
print(epoch+1, total_loss)
test_x, test_y = Variable(test_X), Variable(test_Y)
result = torch.max(model(test_x).data, 1)[1]
accuracy = sum(test_y.cpu().data.numpy() == result.cpu().numpy()) / len(test_y.cpu().data.numpy())
accuracy
정확도가 98.8% 가 나왔다. 98.8로 손글씨를 판별해 내었다.